问题标签 [byte-order-mark]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
php - PHP包含函数输出未知字符
使用 php 包含函数时,包含成功执行,但在输出包含的输出之前它也在输出一个字符,该字符的十六进制值为 3F,我不知道它来自哪里,虽然它似乎每个包含都会发生。
起初我以为是文件编码,但这似乎不是问题。我创建了一个测试用例来演示它:(链接不再工作)http://driveefficiently.com/testinclude.php这个文件只包含:
并且 include.inc 仅包含:
然而,输出是:“?你好,世界”在哪里?是一个具有随机值的字符。正是这个值,我不知道它的起源,它有时会有点搞砸我的网站。
关于这可能来自哪里的任何想法?起初我认为这可能与文件编码有关,但我认为这不是问题。
web-services - CF 中不需要 BOM,但由 IIS/SharePoint 发送
我正在尝试通过 cfinvoke 从 ColdFusion 使用 SharePoint Web 服务(因为我不想处理(阅读:解析)SOAP 响应本身)。
SOAP 响应包含一个字节顺序标记字符 (BOM),它在 CF 中产生以下异常:
UTF-8 编码标准可选地包括 BOM 字符 ( http://unicode.org/faq/utf_bom.html#29 )。Microsoft 几乎普遍包含带有 UTF-8 编码流的 BOM 字符。据我所知,在 IIS 中无法改变它。JRun (ColdFusion) 默认使用的 XML 解析器不处理 UTF-8 编码的 XML 流的 BOM 字符。因此,解决此问题的方法似乎是更改 JRun 使用的 XML 解析器(http://www.bpurcell.org/blog/index.cfm?mode=entry&entry=942)。
Adobe 说它不处理 BOM 字符(请参阅 5 月 2 日和 5 日来自 anonynomous 和 halL 的评论)。
http://livedocs.adobe.com/coldfusion/8/htmldocs/Tags_g-h_09.html#comments
file - 如何为 Unicode 文件设置字节顺序标记?
我知道这不是一个“真正的”编程问题。但是,它与编程有关,所以我还是要设置它。我有一个需要测试的程序,它读取文件的字节顺序标记以查看它是 utf-8 还是 utf-16。我的问题是我找不到允许我设置字节顺序标记的程序/文本编辑器。谁能告诉我如何在文本文件中设置它?
c# - 从 File.ReadAllBytes (byte[]) 中删除字节顺序标记
我有一个 HTTPHandler,它正在读取一组 CSS 文件并将它们组合起来,然后对它们进行 GZipping。但是,一些 CSS 文件包含字节顺序标记(由于 TFS 2005 自动合并中的错误),并且在 FireFox 中,BOM 被作为实际内容的一部分读取,因此它搞砸了我的类名等。我该如何剥离出 BOM 字符?有没有一种简单的方法可以做到这一点,而无需手动通过字节数组寻找“”?
.net - XML - 根级别的数据无效
我有一个以 UTF-8 编码的 XSD 文件,我运行它的任何文本编辑器都不会在文件开头显示任何字符,但是当我在 Visual Studio 的调试器中将其拉起时,我清楚地看到一个空的文件前面的框。
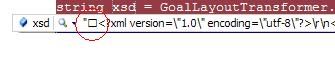
我也得到错误:
根级别的数据无效。第 1 行,位置 1。
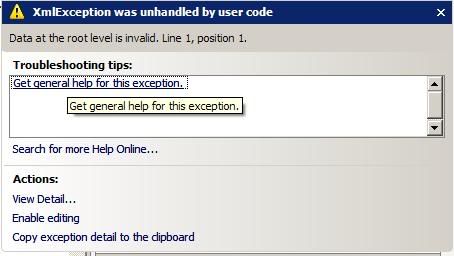
有谁知道这是什么吗?
更新:编辑帖子以限定文件类型。它是由 Microsoft 的 XSD 创建者创建的 XSD 文件。
xml - 如何从我的 xml 文件中删除 BOM 字符
我正在使用 xsl 来控制我的 xml 文件的输出,但是正在添加 BOM 字符。
algorithm - 当 BOM(字节顺序标记)丢失时,如何最好地猜测编码?
我的程序必须读取使用各种编码的文件。它们可能是 ANSI、UTF-8 或 UTF-16(大端或小端)。
当 BOM(字节顺序标记)在那里时,我没有问题。我知道文件是 UTF-8 还是 UTF-16 BE 或 LE。
我想假设当没有 BOM 文件是 ANSI 时。但我发现我正在处理的文件经常缺少它们的 BOM。因此,没有 BOM 可能意味着文件是 ANSI、UTF-8、UTF-16 BE 或 LE。
当文件没有 BOM 时,扫描某些文件并最准确地猜测编码类型的最佳方法是什么?如果文件是 ANSI,我希望接近 100% 的时间,如果文件是 UTF 格式,我希望接近 100%。
我正在寻找一种通用的算法方法来确定这一点。但我实际上使用的是 Delphi 2009,它知道 Unicode 并且有一个 TEncoding 类,所以特定的东西将是一个奖励。
回答:
ShreevatsaR 的回答让我在 Google 上搜索“通用编码检测器 delphi”,这让我感到惊讶的是,这篇文章在仅存活了大约 45 分钟后就被列为第一名!那是快速的googlebotting!Stackoverflow 如此迅速地获得第一名也令人惊讶。
Google 中的第二篇文章是 Fred Eaker 撰写的关于字符编码检测的博客文章,其中列出了各种语言的算法。
我在那个页面上发现了 Delphi,它直接把我带到了 SourceForge 的 Free OpenSource ChsDet Charset Detector,它是用 Delphi 编写的,基于 Mozilla 的 i18n 组件。
极好的!感谢所有回答的人(全部 +1),感谢 ShreevatsaR,再次感谢 Stackoverflow,帮助我在不到一个小时的时间内找到答案!
c# -  字符附加到每个文件的开头
我已经下载了一个 HttpHandler 类,它将 JS 文件连接到一个文件中,并且它不断在它连接的每个文件的开头附加字符。
关于造成这种情况的任何想法?是不是一旦处理过的文件被写入缓存,缓存就是这样存储/呈现它的?
任何输入将不胜感激。
ruby - 读取文件时如何避免绊倒 UTF-8 BOM
我正在使用最近添加了 Unicode BOM 标头 (U+FEFF) 的数据馈送,而我的 rake 任务现在被它搞砸了。
我可以跳过前 3 个字节,file.gets[3..-1]但是有没有更优雅的方式来读取 Ruby 中的文件,它可以正确处理这个问题,无论 BOM 是否存在?
java - Java 是否有获取各种字节顺序标记的方法?
我正在寻找一种实用方法或 Java 中的常量,它将返回与编码的适当字节顺序标记相对应的字节,但我似乎找不到。有吗?我真的很想做类似的事情:
CharEncoding来自 Apache Commons 。