问题标签 [apache-spark-ml]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
apache-spark - 如何交叉验证 RandomForest 模型?
我想评估一个正在对某些数据进行训练的随机森林。Apache Spark 中是否有任何实用程序可以执行相同操作,还是我必须手动执行交叉验证?
pyspark - 使用 ML spark 和数据帧进行隐式推荐
我正在尝试使用带有 Spark 和 Dataframes 的新 ML 库来构建具有隐式评级的推荐器。我的代码
但是,我在这个错误中运行
pyspark.sql.utils.AnalysisException:无法解析给定输入列用户、项目的“评级”;
所以,不知道如何定义数据框
python - 在 PySpark 中编码和组装多个功能
我有一个 Python 类,用于在 Spark 中加载和处理一些数据。在我需要做的各种事情中,我正在生成一个从 Spark 数据帧中的各个列派生的虚拟变量列表。我的问题是我不确定如何正确定义用户定义函数来完成我所需要的。
我目前确实有一个方法,当映射到底层数据帧 RDD 时,解决了一半的问题(请记住,这是一个更大的data_processor类中的方法):
本质上,对于指定的数据框,它的作用是获取指定列的分类变量值,并返回这些新虚拟变量的值列表。这意味着以下代码:
返回类似:
这正是我在生成我想要的虚拟变量列表方面想要的,但这是我的问题:我怎样才能(a)制作一个具有类似功能的 UDF,我可以在 Spark SQL 查询中使用(或其他方式) ,我想),还是(b)获取上述地图产生的RDD并将其作为新列添加到user_data数据框?
无论哪种方式,我需要做的是生成一个新的数据框,其中包含来自 user_data 的列,以及一个feature_array包含上述函数输出(或功能等效的东西)的新列(我们称之为它)。
apache-spark - 保存 ML 模型以供将来使用
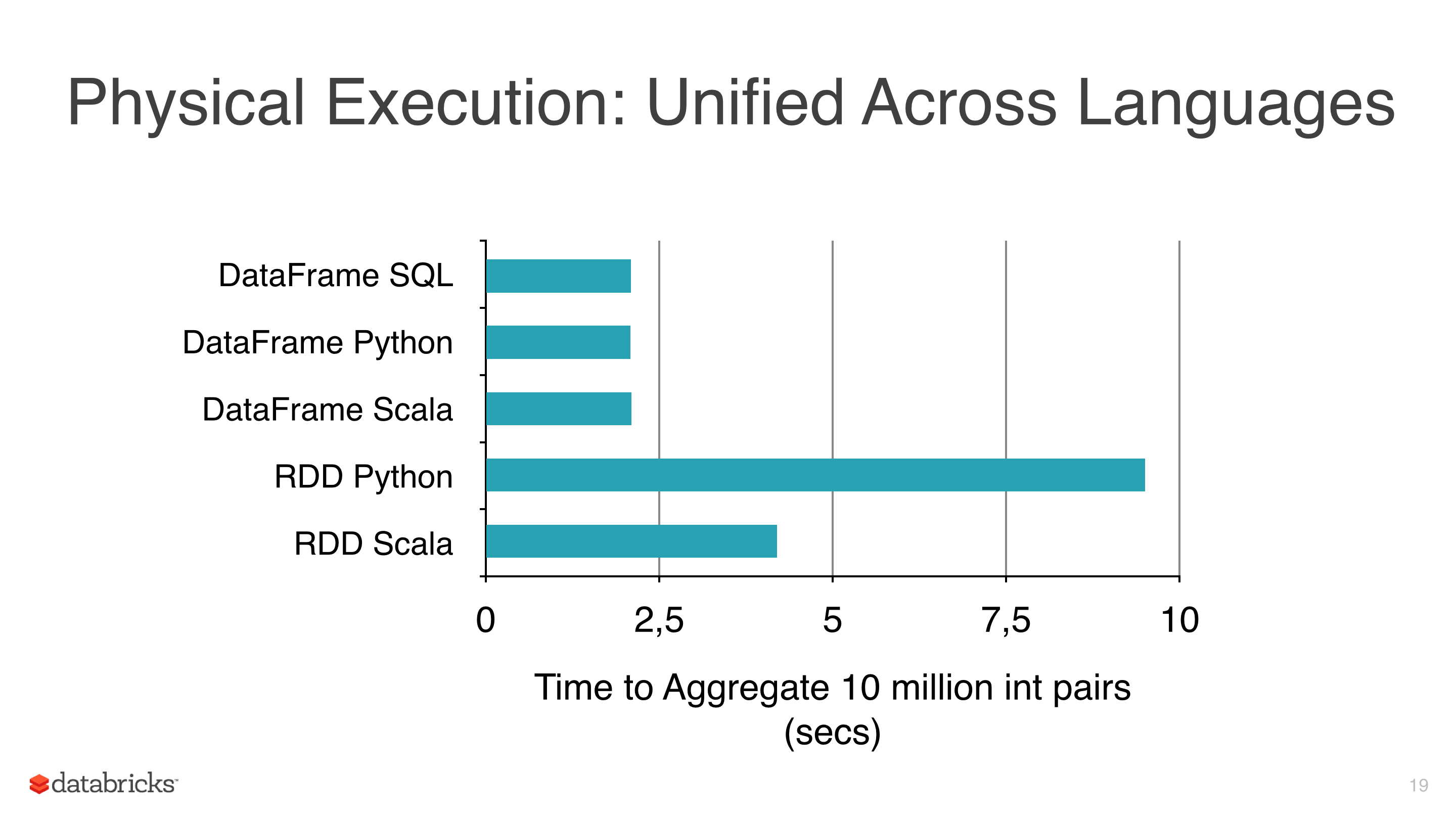
我正在对一些数据应用一些机器学习算法,如线性回归、逻辑回归和朴素贝叶斯,但我试图避免使用 RDD 并开始使用 DataFrame,因为RDD比 pyspark 下的 Dataframe慢(见图 1)。
我使用 DataFrames 的另一个原因是因为 ml 库有一个对调整模型非常有用的类是CrossValidator这个类在拟合它之后返回一个模型,显然这个方法必须测试几个场景,然后返回一个拟合模型(具有最佳参数组合)。
我使用的集群不是很大,数据也很大,有些拟合需要几个小时,所以我想保存这些模型以便以后重用它们,但我还没有意识到如何,有什么我忽略的吗?
笔记:
- mllib 的模型类有一个 save 方法(即NaiveBayes),但 mllib 没有 CrossValidator 并使用 RDD,所以我有预谋地避免它。
- 当前版本是火花 1.5.1。
scala - Spark DataFrame 在 OneHotEncoder 中处理空字符串
我正在将一个 CSV 文件(使用 spark-csv)导入一个DataFrame具有空String值的文件中。应用时OneHotEncoder,应用程序崩溃并出现错误requirement failed: Cannot have an empty string for name.。有没有办法解决这个问题?
我可以重现Spark ml页面上提供的示例中的错误:
这很烦人,因为缺失/空值是一种高度通用的情况。
在此先感谢,尼基尔
scala - 是否可以访问 spark.ml 管道中的估计器属性?
我在 Spark 1.5.1 中有一个 spark.ml 管道,它由一系列转换器和一个 k-means 估计器组成。我希望能够在安装管道后访问KMeansModel .clusterCenters,但不知道如何。是否有 spark.ml 等效于 sklearn 的 pipeline.named_steps 功能?
我找到了这个答案,它提供了两种选择。如果我将 k-means 模型从我的管道中取出并单独安装,则第一个有效,但这有点违背了管道的目的。第二个选项不起作用 - 我得到error: value getModel is not a member of org.apache.spark.ml.PipelineModel.
编辑:示例管道:
所以现在fitKmeans是类型org.apache.spark.ml.PipelineModel。我的问题是,如何访问由该管道中包含的 k-means 模型计算的集群中心?如上所述,当不包含在管道中时,可以使用fitKmeans.clusterCenters.
machine-learning - 为什么 spark.ml 不实现任何 spark.mllib 算法?
根据Spark MLlib 指南 ,我们可以看到 Spark 有两个机器学习库:
spark.mllib,建立在 RDD 之上。spark.ml,建立在数据框之上。
根据这个和StackOverflow 上的这个问题,Dataframes 比 RDD 更好(而且更新),应该尽可能使用。
问题是我想使用常见的机器学习算法(例如:频繁模式挖掘、朴素贝叶斯等)并且spark.ml(对于数据帧)不提供这种方法,只有spark.mllib(对于 RDD)提供这种算法。
如果 Dataframes 比 RDDs 更好,并且参考指南建议使用spark.ml,为什么不在该库中实现常见的机器学习方法?
这里缺少什么?
apache-spark - 检查点 RDD ReliableCheckpointRDD 的分区数与原始 RDD 不同
我有两台机器的火花集群,当我运行火花流应用程序时,我收到以下错误:
如何在不是 HDFS/Cassandra/任何其他数据存储的文件系统上提供检查点目录?
我想到了两种可能的解决方案,但我不知道如何编码:
有一个远程目录,对两个工作人员都是本地的
为两个工作人员指定一个远程目录
有什么建议么 ?
apache-spark - 如何在 DataFrame 中合并多个特征向量?
使用 Spark ML 转换器,我到达了DataFrame每行如下所示的位置:
其中text_features是术语权重的稀疏向量,color_features是一个小的 20 元素(one-hot-encoder)密集颜色向量,type_features也是一个 one-hot-encoder 密集类型向量。
将这些特征合并到一个大数组中的好方法是什么(使用 Spark 的工具),以便我测量任何两个对象之间的余弦距离之类的东西?
java - 如何对单词列表进行特征提取?
我正在使用 Apache Spark ML(通过 Java API)来分析一些自由文本。我想构建一个管道来提取一个特征,该特征指示是否存在任何预配置的术语列表。
CountVectorizer似乎几乎可以做我所追求的,但我想预先指定一个词汇表。到目前为止,我有:
有没有办法在 Spark ML 中做到这一点?我需要自己写Transformer吗?