matlab FAQ 描述了一种查找局部最大值的单行方法:
index = find( diff( sign( diff([0; x(:); 0]) ) ) < 0 );
但我相信这只有在数据或多或少平滑的情况下才有效。假设您有数据以小间隔上下跳跃,但仍有一些近似的局部最大值。您将如何找到这些点?您可以将向量分成 n 部分,并找到不在每个部分边缘的最大值,但应该有一个更优雅和更快的解决方案。
单线解决方案也很棒。
编辑:我正在处理嘈杂的生物图像,我试图将它们分成不同的部分。
我不确定您正在处理什么类型的数据,但这是我用来处理语音数据的一种方法,可以帮助您找到局部最大值。它使用信号处理工具箱中的三个函数:HILBERT、BUTTER和FILTFILT。
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
然后,您将在smoothData上执行最大值查找。使用 HILBERT 首先在数据上创建一个正包络,然后 FILTFILT 使用来自 BUTTER 的滤波器系数对数据包络进行低通滤波。
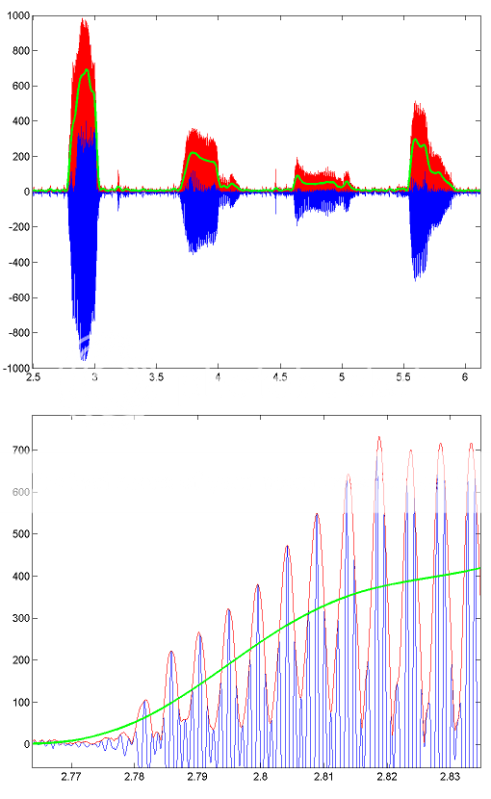
有关此处理如何工作的示例,这里有一些图像显示了一段录制语音的结果。蓝线是原始语音信号,红线是包络(使用 HILBERT 获得),绿线是低通滤波结果。下图是第一个的放大版本。
随机尝试:
这是我起初的一个随机想法......您可以尝试通过找到最大值的最大值来重复该过程:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
但是,根据信噪比,不清楚需要重复多少次才能获得您感兴趣的局部最大值。这只是一个随机的非过滤选项。=)
最大发现:
以防你好奇,我见过的另一种单线最大值查找算法(除了你列出的那个)是:
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
根据您的需要,过滤噪声数据通常很有帮助。看看MEDFILT1,或者使用CONV和FSPECIAL。在后一种方法中,您可能希望使用 CONV 的“相同”参数和 FSPECIAL 创建的“高斯”过滤器。
完成过滤后,将其输入最大值查找器。
编辑: 运行时复杂性
假设输入向量的长度为 X,滤波器内核长度为 K。
中值滤波器可以通过运行插入排序来工作,所以它应该是 O(X K + K log K)。没看源码,其他实现也是可以的,但基本上应该是O(X K)。
当 K 较小时,conv 使用直接的 O(X*K) 算法。当 X 和 K 几乎相同时,使用快速傅立叶变换会更快。该实现是 O(X log X + K log K)。Matlab 足够聪明,可以根据输入大小自动选择正确的算法。
如果您的数据上下跳跃很多,那么该函数将有许多局部最大值。所以我假设你不想找到所有的局部最大值。但是,您对局部最大值的标准是什么?如果您有一个标准,那么可以为此设计一个方案或算法。
我现在猜想也许你应该先对你的数据应用一个低通滤波器,然后找到局部最大值。尽管过滤后的局部最大值的位置可能与之前的位置不完全对应。
有两种方法可以查看此类问题。人们可以将其视为主要的平滑问题,使用过滤工具对数据进行平滑处理,然后才使用各种插值(可能是插值样条)进行插值。找到插值样条的局部最大值是一件很容易的事情。(请注意,您通常应该在这里使用真正的样条,而不是 pchip 插值。在 interp1 中指定“三次”插值时采用的方法 Pchip 不会准确定位落在两个数据点之间的局部最小值。)
解决此类问题的另一种方法是我倾向于使用的方法。这里使用最小二乘样条模型来平滑数据并产生近似值而不是插值。这种最小二乘样条具有允许用户大量控制将他们对问题的知识引入模型的优点。例如,科学家或工程师通常拥有关于所研究过程的信息,例如单调性。这可以构建到最小二乘样条模型中。另一个相关的选项是使用平滑样条。它们也可以通过内置的正则化约束来构建。如果您有样条工具箱,那么 spap2 将具有适合样条模型的一些实用程序。然后 fnmin 会找到一个最小化器。(最大化器很容易从最小化代码中获得。)
当数据点等距时,采用过滤方法的平滑方案通常最简单。不等间距可能会推动最小二乘样条模型。另一方面,结位置可能是最小二乘样条中的一个问题。我在所有这些中的观点是表明任何一种方法都有优点,并且可以产生可行的结果。