我正在尝试监视使用 CUDA 和 MPI 的进程,有什么办法可以做到这一点,例如命令“top”,但也监视 GPU?
234016 次
16 回答
217
要实时了解已用资源,请执行以下操作:
nvidia-smi -l 1
这将每秒循环并调用视图。
如果您不想在控制台历史记录中保留循环调用的过去痕迹,您还可以执行以下操作:
watch -n0.1 nvidia-smi
其中 0.1 是时间间隔,以秒为单位。

于 2016-03-03T07:33:43.907 回答
138
我发现gpustat非常有用。可以安装pip install gpustat,并按进程或用户打印使用明细。

于 2018-07-18T15:43:50.870 回答
86
我不知道有什么可以结合这些信息的,但是您可以使用该nvidia-smi工具来获取原始数据,就像这样(感谢@jmsu 提供关于 -l 的提示):
$ nvidia-smi -q -g 0 -d UTILIZATION -l
==============NVSMI LOG==============
Timestamp : Tue Nov 22 11:50:05 2011
Driver Version : 275.19
Attached GPUs : 2
GPU 0:1:0
Utilization
Gpu : 0 %
Memory : 0 %
于 2011-11-22T10:43:43.560 回答
28
只需使用watch nvidia-smi,它会默认以 2s 的间隔输出消息。
例如,如下图:

您也可以使用watch -n 5 nvidia-smi(-n 5 x 5s 间隔)。
于 2018-06-29T03:29:26.993 回答
23
使用参数“--query-compute-apps=”
nvidia-smi --query-compute-apps=pid,process_name,used_memory --format=csv
如需进一步帮助,请关注
nvidia-smi --help-query-compute-app
于 2017-04-25T14:01:24.020 回答
20
您可以尝试nvtop,它类似于广泛使用的htop工具,但适用于 NVIDIA GPU。这是它的运行截图nvtop。

于 2019-03-09T12:46:55.693 回答
19
从此处下载并安装最新的稳定 CUDA 驱动程序 (4.2) 。在 linux 上,nVidia-smi 295.41 为您提供您想要的。使用nvidia-smi:
[root@localhost release]# nvidia-smi
Wed Sep 26 23:16:16 2012
+------------------------------------------------------+
| NVIDIA-SMI 3.295.41 Driver Version: 295.41 |
|-------------------------------+----------------------+----------------------+
| Nb. Name | Bus Id Disp. | Volatile ECC SB / DB |
| Fan Temp Power Usage /Cap | Memory Usage | GPU Util. Compute M. |
|===============================+======================+======================|
| 0. Tesla C2050 | 0000:05:00.0 On | 0 0 |
| 30% 62 C P0 N/A / N/A | 3% 70MB / 2687MB | 44% Default |
|-------------------------------+----------------------+----------------------|
| Compute processes: GPU Memory |
| GPU PID Process name Usage |
|=============================================================================|
| 0. 7336 ./align 61MB |
+-----------------------------------------------------------------------------+
编辑:在最新的 NVIDIA 驱动程序中,这种支持仅限于 Tesla 卡。
于 2012-09-26T19:05:46.287 回答
18
另一种有用的监控方法是对ps消耗 GPU 的进程使用过滤。我经常使用这个:
ps f -o user,pgrp,pid,pcpu,pmem,start,time,command -p `lsof -n -w -t /dev/nvidia*`
这将显示所有使用 nvidia GPU 的进程以及有关它们的一些统计信息。lsof ...使用当前用户拥有的 nvidia GPU 检索所有进程的列表,并ps -p ...显示ps这些进程的结果。ps f显示子/父进程关系/层次结构的良好格式,并-o指定自定义格式。这类似于只是做ps u,但添加了进程组 ID 并删除了一些其他字段。
这样做的一个优点nvidia-smi是它将显示进程分支以及使用 GPU 的主进程。
但是,一个缺点是它仅限于执行命令的用户拥有的进程。为了向任何用户拥有的所有进程开放它,我sudo在lsof.
最后,我结合它watch来获得持续更新。所以,最后,它看起来像:
watch -n 0.1 'ps f -o user,pgrp,pid,pcpu,pmem,start,time,command -p `sudo lsof -n -w -t /dev/nvidia*`'
其输出如下:
Every 0.1s: ps f -o user,pgrp,pid,pcpu,pmem,start,time,command -p `sudo lsof -n -w -t /dev/nvi... Mon Jun 6 14:03:20 2016
USER PGRP PID %CPU %MEM STARTED TIME COMMAND
grisait+ 27294 50934 0.0 0.1 Jun 02 00:01:40 /opt/google/chrome/chrome --type=gpu-process --channel=50877.0.2015482623
grisait+ 27294 50941 0.0 0.0 Jun 02 00:00:00 \_ /opt/google/chrome/chrome --type=gpu-broker
grisait+ 53596 53596 36.6 1.1 13:47:06 00:05:57 python -u process_examples.py
grisait+ 53596 33428 6.9 0.5 14:02:09 00:00:04 \_ python -u process_examples.py
grisait+ 53596 33773 7.5 0.5 14:02:19 00:00:04 \_ python -u process_examples.py
grisait+ 53596 34174 5.0 0.5 14:02:30 00:00:02 \_ python -u process_examples.py
grisait+ 28205 28205 905 1.5 13:30:39 04:56:09 python -u train.py
grisait+ 28205 28387 5.8 0.4 13:30:49 00:01:53 \_ python -u train.py
grisait+ 28205 28388 5.3 0.4 13:30:49 00:01:45 \_ python -u train.py
grisait+ 28205 28389 4.5 0.4 13:30:49 00:01:29 \_ python -u train.py
grisait+ 28205 28390 4.5 0.4 13:30:49 00:01:28 \_ python -u train.py
grisait+ 28205 28391 4.8 0.4 13:30:49 00:01:34 \_ python -u train.py
于 2016-06-06T18:15:15.753 回答
11
最近,我写了一个监控工具nvitop,叫做交互式NVIDIA-GPU 进程查看器。
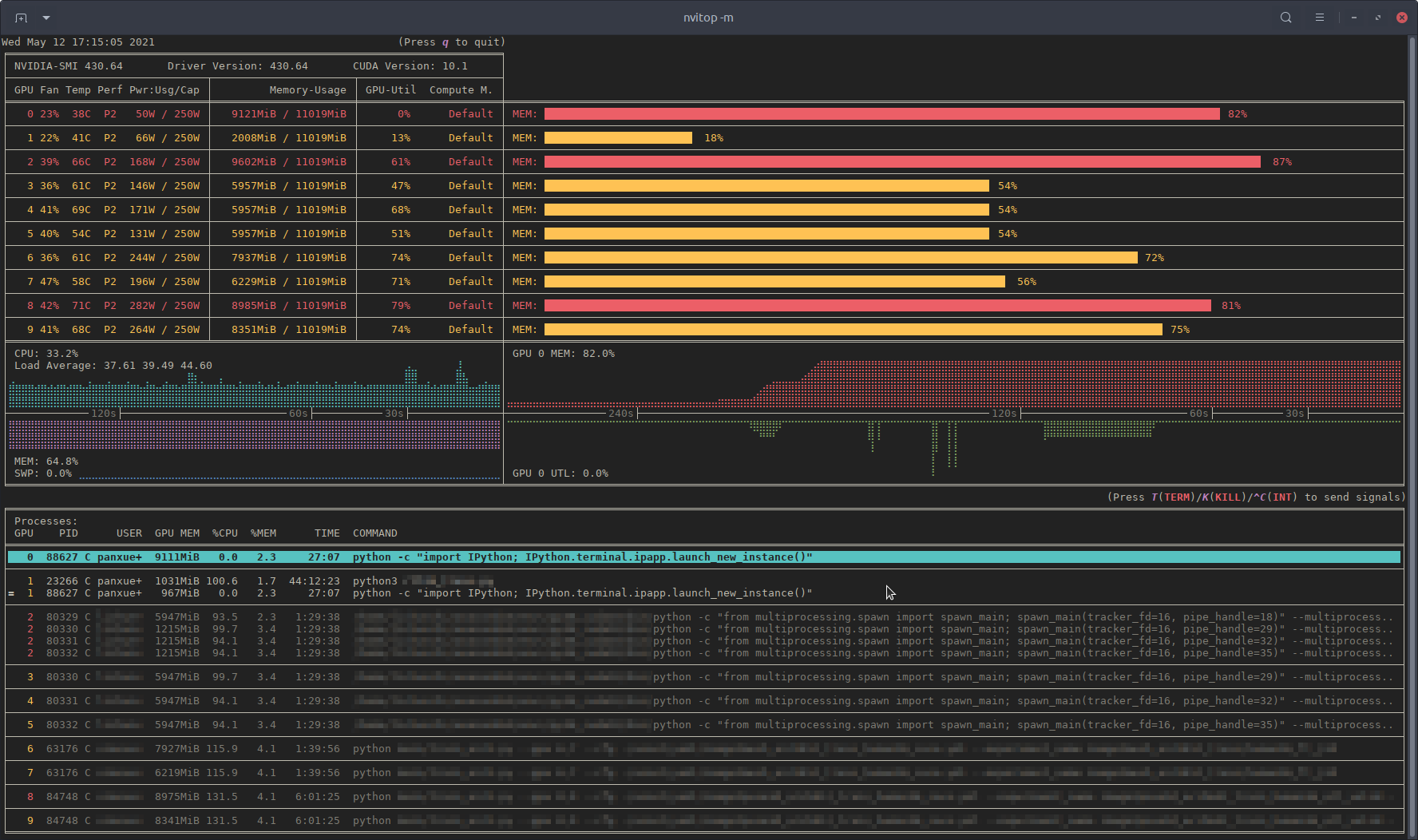
它是用纯 Python 编写的,易于安装。
从 PyPI 安装:
pip3 install --upgrade nvitop
从 GitHub 安装最新版本(推荐):
pip3 install git+https://github.com/XuehaiPan/nvitop.git#egg=nvitop
作为资源监视器运行:
nvitop -m
nvitop将显示 GPU 状态,nvidia-smi但带有额外的花哨的条形图和历史图。
对于流程,它将psutil用于收集流程信息并显示USER、%CPU、%MEM、TIME和COMMAND字段,这比nvidia-smi. 此外,它还可以响应监控模式下的用户输入。您可以中断或终止GPU 上的进程。
nvitop带有树视图屏幕和环境屏幕:


此外,nvitop还可以集成到其他应用程序中。例如,集成到 PyTorch 训练代码中:
import os
from nvitop.core import host, Device, HostProcess, GpuProcess
from torch.utils.tensorboard import SummaryWriter
device = Device(0)
this_process = GpuProcess(os.getpid(), device)
writer = SummaryWriter()
for epoch in range(n_epochs):
# some training code here
# ...
this_process.update_gpu_status()
writer.add_scalars(
'monitoring',
{
'device/memory_used': float(device.memory_used()) / (1 << 20), # convert bytes to MiBs
'device/memory_utilization': device.memory_utilization(),
'device/gpu_utilization': device.gpu_utilization(),
'host/cpu_percent': host.cpu_percent(),
'host/memory_percent': host.memory_percent(),
'process/cpu_percent': this_process.cpu_percent(),
'process/memory_percent': this_process.memory_percent(),
'process/used_gpu_memory': float(this_process.gpu_memory()) / (1 << 20), # convert bytes to MiBs
},
global_step
)
有关详细信息,请参阅https://github.com/XuehaiPan/nvitop 。
注意:nvitop是在GPLv3 许可下发布的。请随意将其用作您自己项目的包或依赖项。但是,如果您想添加或修改 的某些功能nvitop,或者将某些源代码复制nvitop到自己的代码中,则源代码也应在 GPLv3 许可下发布。
于 2021-05-19T07:51:35.750 回答
6
这可能不优雅,但你可以尝试
while true; do sleep 2; nvidia-smi; done
我也尝试了@Edric 的方法,该方法有效,但我更喜欢nvidia-smi.
于 2015-11-10T00:02:40.897 回答


3
如果你只想找到在 gpu 上运行的进程,你可以简单地使用以下命令:
lsof /dev/nvidia*
对我来说 nvidia-smi,watch -n 1 nvidia-smi在大多数情况下就足够了。有时nvidia-smi显示没有进程,但 gpu 内存已用完,所以我需要使用上述命令来查找进程。
于 2019-10-22T12:32:00.873 回答
3
在 Linux Mint 和最有可能的 Ubuntu 中,您可以尝试“nvidia-smi --loop=1”
于 2020-02-27T22:58:39.820 回答
2
我在 Windows 机器中创建了一个带有以下代码的批处理文件,以每秒进行监控。这个对我有用。
:loop
cls
"C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi"
timeout /T 1
goto loop
如果您只想运行一次命令,nvidia-smi exe 通常位于“C:\Program Files\NVIDIA Corporation”。
于 2019-06-14T12:28:11.120 回答
0
有利用 nvidai-smi 二进制文件的Prometheus GPU Metrics Exporter (PGME)。你可以试试这个。运行导出器后,您可以通过http://localhost:9101/metrics访问它。对于两个 GPU,示例结果如下所示:
temperature_gpu{gpu="TITAN X (Pascal)[0]"} 41
utilization_gpu{gpu="TITAN X (Pascal)[0]"} 0
utilization_memory{gpu="TITAN X (Pascal)[0]"} 0
memory_total{gpu="TITAN X (Pascal)[0]"} 12189
memory_free{gpu="TITAN X (Pascal)[0]"} 12189
memory_used{gpu="TITAN X (Pascal)[0]"} 0
temperature_gpu{gpu="TITAN X (Pascal)[1]"} 78
utilization_gpu{gpu="TITAN X (Pascal)[1]"} 95
utilization_memory{gpu="TITAN X (Pascal)[1]"} 59
memory_total{gpu="TITAN X (Pascal)[1]"} 12189
memory_free{gpu="TITAN X (Pascal)[1]"} 1738
memory_used{gpu="TITAN X (Pascal)[1]"} 10451
于 2018-06-12T18:11:56.867 回答
0
您可以nvidia-smi pmon -i 0用来监控 GPU 0 中的每个进程。包括计算模式、sm 使用情况、内存使用情况、编码器使用情况、解码器使用情况。
于 2019-01-16T08:51:08.877 回答