我听说过很多关于语义网的信息,但我仍然不确定它是什么。它与我们现在所知道的网络有何不同?
5049 次
10 回答
41
最好的解释是举例。尝试使用谷歌搜索所有在网络上宣传的汽车,这些汽车的发动机小于 2.0 升,无铅运行,有 mp3 连接,并且可以在从我家乘坐公共交通工具方便到达的陈列室中看到。
谷歌将无法帮助您进行该查询,不是真的。您必须自己进行多次搜索并关联结果。在语义网络上,您可以表达对汽车销售产品的兴趣,并添加约束。每个结果都会很有用。一个或多个 UI 可能使您能够做到这一点,有些可能是专门的,有些则完全通用。
另一个例子,创建一个通常不存储在一个地方的东西的图表,比如健怡可乐的受欢迎程度,或者人群中的乡村散步与同一人群中的临床肥胖水平。对于这些,您可能根本不使用 Web 浏览器,但可能会使用更像 Excel 的东西- 但语义 Web 为您提供了工具(SPARQL、RDF),用于查找和操作现有数据并且可通过 HTTP 访问。
因此,Bravax 提出的观点并不完全正确,不会有太大变化——您可能只是获得了一些更有用和更好的 mashup 网站。或者,您可能会发现自己做了很多在今天之前从未想过与网络相关的事情。
当前的网络有很多替代方法可以做同样的事情,比如动画 GIF、Flash、Silverlight、DHTML 等。为了将数据放在语义网络上,会有一系列工具和格式。RDFa 是一个很好的,一种更通用的微格式,但是您可以提供整个数据库的转储,公开SPARQL 端点,使用微格式或专有的 HTML 结构并添加转换,会有很多工具来适应不同的案例。
所以 Vartec 也是部分正确的,你可以使用 RDFa 和 eRDF,但你也可以使用很多其他的东西来发布数据。
请注意,语义网络和另一个称为关联数据的简单概念之间有很多重叠之处。它们之间的关系尚不清楚,但我的看法是,在语义 Web 工具和技术有任何作用之前,您需要链接数据网络。关联数据是关于数据的,语义网更多的是关于处理数据、对其进行推理以及处理诸如信任可靠性之类的问题。本质上是技术栈的底层几层。
于 2009-04-07T12:37:28.473 回答
13
语义网本质上是一个非常简单的想法。(就像所有的好人一样。)
目前的 Web 由文档组成,文档之间有链接。谷歌通过使用上下文和链接中的锚文本来确定链接的含义并基于此构建用于检索数据的引擎,从而取得了相当不错的业务。换句话说,谷歌猜测链接的语义是什么。
语义网的想法是“如果输入这些链接会怎样?” Web 上的每个事实都有一个地址 - 一个 URI - 并通过关系(也是URI)链接到其他事实(也是URI)。关系组称为“本体”。
因此,与当前 Web 上的 A 页面链接到 B 页面不同,语义 Web 上的链接更像:
URI A 使用 URI C 类型的链接链接到 URI B。
任何东西都可以有一个 URI。人们可以有 URI;通常我们使用一组称为 FOAF 的关系来描述它们。假设 Jeff Atwood 的 URI 是http://codinghorror.com/foaf.xml;那么你可以说:
< http://codinghorror.com >< http://xmlns.com/foaf/0.1/homepage >< http://codinghorror.com/foaf.xml >
即http://codinghorror.com是 http://codinghorror.com/foaf.xml 的内容所代表的人的主页。
现在机器可以读取和查询这些关系——因此您可以将 Web 变成计算机可以立即使用的数据库。Semantic Web 查询语言是 SPARQL,值得一试。
于 2009-04-07T12:44:38.893 回答
4
语义网就是这样——位于万维网之上的语义(有意义的)层。它是半结构化的 (RDF),它是自描述的(使用 OWL 的本体),并允许资源发现 (SPARQL)。
语义网在“开放世界”假设的前提下工作;仅仅因为没有说明某事并不意味着它不存在,它只是“未知”。这与 MySQL 等 RDBMS 中使用的逻辑完全不同。- 如果缺少某些东西,它就不存在 - “封闭世界”假设。Prolog 和 DATALOG 是 Close World 逻辑的好例子。
如果你想真正了解底层发生了什么,你需要看看它的基础,它位于描述逻辑中。可以在这里找到描述逻辑的一个很好的概述:http: //www.inf.unibz.it/~franconi/dl/course/
如果您想了解有关 RDF 的更多信息,请阅读RDF Primer。RDF Semantics是另一本轰动一时的读物。
研究人员基本上已经放弃了语义网的“语义”部分,并决定专注于关联数据——如何导航 RDF 三元组,以便我们可以浪费更多的互联网带宽;-)
于 2009-06-23T06:48:54.147 回答
2
目前,对于 HTML 页面,我们有标记标签来描述应该如何显示内容,<b>, '<pre>等。这些标签对它们的内容没有任何意义。
语义网的概念是文档将包含确实暗示其内容含义的 XML 标记。例如<person><firstname>. 伟大的想法是 CSS 将能够格式化此类文档,但也可以轻松地从这些文档中提取有意义的信息。
于 2009-04-07T11:46:22.967 回答
2
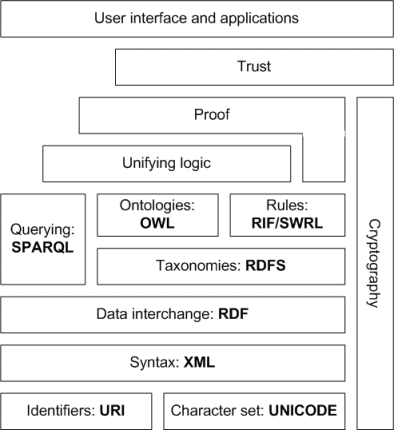
语义网是万维网的发明者蒂姆·伯纳斯-李(Tim Berners-Lee)真正想要的万维网——即相互关联的数据的全球图。它是社交图谱的概括,您可以在其中使用社交数据(使用诸如FOAF之类的词汇表)以及任何其他类型的机器可理解的数据并将它们相互连接。向机器描述此信息的标准格式是资源描述格式 ( RDF ) 和 Web 本体语言 ( OWL )。Web 上已经有很多编码数据,包括一个 RDF 版本的 Wikipedia,称为DBPedia。
语义网将不同于今天的网络,因为计算机和人类都将理解文档包含什么以及文档之间链接的重要性。这将促进信息处理任务的自动化,包括从可靠来源研究信息。完整的 SemWeb 堆栈包括密码学、证明系统和信任网络。
{kind=link}
于 2009-04-07T15:49:32.443 回答
2
Tim Berners-Lee在他的博文Giant Global Graph(从 2007-11-21)中描述了它:
三个心理动作:
- 互联网:“有趣的不是电缆,而是计算机”
- (万维网)网络:“有趣的不是计算机,而是文档”
- Giant Global Graph:“重要的不是文件,而是文件所涉及的内容”
关于“巨型全局图”一词:
现在,我们可以使用 Graph 一词来与 Web 区分开来。
我将此图称为语义网,但也许它应该是巨型全球图!比 WWWW 还差吗?;-) “语义网”这个术语已经建立了很长时间,我不打算改变它。但是让我们想想它是什么图。(脚注:“Graph”也恰好是 RDF 规范使用的词,但顺便说一下。当 XML 解析器创建 DOM 树时,RDF 解析器在内存中创建 RDF 图。)
于 2012-08-27T10:37:26.617 回答
1
语义网是迄今为止提出的修复万维网固有设计缺陷的唯一实用解决方案。因为正如我们今天所知,互联网的设计者并没有提供机制来解决支配人类思考和交流方式的基本语言现象,例如同音异义词、同义词等。在互联网上搜索信息会导致大量虚假信息积极的一面。语义网的想法归结为为网络资源分配明确的标识符,这将有助于正确识别它们的含义。如果有一天它成功了,我们可能会忘记通常的谷歌搜索是什么样子的,如果它失败了,一切都将保持现在的状态。
于 2013-06-21T09:17:59.280 回答
0
这是一个吸引人们兴趣的流行语,类似于Web 2.0
即在未来的内容将从演示中分离出来,允许很多好处。
实际上,事实将是主观的,取决于主持人的真实性和权威性。
换句话说,从现在开始,用户不会看到太大的不同。
于 2009-04-07T11:52:21.390 回答
0
语义网是一个分布式信息系统,其中相互关联的数据通过 HTTP 以 RDF 三元组的形式发布。RDF 三元组由主语、谓语和宾语组成,但可以附加其他东西,例如关于对象自然语言的数据类型和注释。在语义 Web 上,URI 既用作标识符,也用作网络资源的地址。
它与 Web 不同,因为 Web 是文档和应用程序接口的分布式信息系统。
于 2009-04-07T13:44:33.180 回答