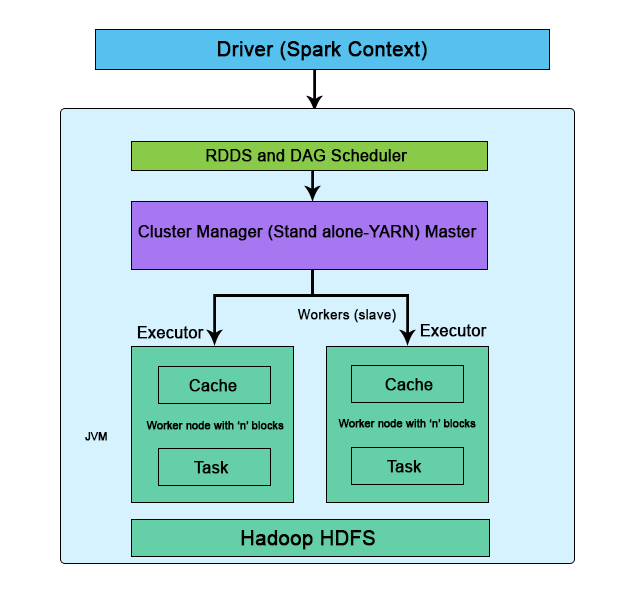
Apache Spark处理 250-500 GB 数据的工作负载。B/M 是用 100% 和 10% 的数据集完成的。根据类型和大小,作业在 250-3000 秒之间运行。我可以使用 1 个执行器核心强制执行器的数量为 1,但这是错误的,因为理论上应该只编写最佳的串行作业。
– 24 分钟前静止
(添加 URL)

感谢您的注意。问题得到解决:
Q : ... "CS 中是否使用了这样的参数?"
关于上述问题的观察问题的答案与 DATA 大小本身无关,DATA 大小很重要,但核心理解与开销很重要的分布式计算的内部功能有关:
SMALL RDD-DATA
+-------------------E-2-E ( RDD/DAG Spark-wide distribution
|s+------+o | & recollection
|e| | v s| Turn-Around-Time )
|t| DATA | e d |
|u|1x | r a |
|p+------+ h e |
+-------------------+
| |
| |
|123456789.123456789|
然而 :
LARGER RDD-DATA
+--------:------:------:------:-------------------E-2-E ( RDD/DAG Spark-wide TAT )
|s+------:------:------:------:------+o + |
|e| : : : : | v s v|
|t| DATA : DATA : DATA : DATA : DATA | e d a|
|u|1x :2x :3x :4x :5x | r a r|
|p+------:------:------:------:------+ h e .|
+--------:------:------:------:-------------------+
| |
| | |
|123456789.123456789| |
| |
|123456789.123456789.123456789.123456789.123456789|
( not a multiple of 5x the originally observed E-2-E for "small" DATA ( Spark-wide TAT )
yet a ( Setup & Termination overheads stay about same ~ const. )
a ( a DATA-size variable part need-not yet may grow )
now
show an E-2-E of about ~ 50 TimeUNITs for 5-times more DATA,
that is
for obvious
reasons not 5-times ~ 20 TimeUNITs
as was seen
during the E-2-E TAT from processing in "small"-DATA use-case
as not
all system-wide overheads accumulation
scale with DATA size
如需进一步阅读 Amdahl 的论点和 Gustafson/Barsis 推广的缩放,请随时在此处继续。
{kind=link}