如何避免不必要的 CPU 开销?
通过失败测试查看这个历史性问题。示例:j->'x'是一个表示数字和j->'y'布尔值的 JSONb。从 JSONb 的第一个版本(2014 年发布 9.4)到今天(6 年!),使用 PostgreSQL v12... 似乎我们需要强制执行双重转换:
丢弃
j->'x'“二进制 JSONb 数字”信息,并将其转换为可打印字符串j->>'x';
丢弃j->'y'“二进制 JSONb 布尔”信息并将其转换为可打印字符串j->>'y'。通过转换字符串解析字符串以获得“二进制 SQL 浮点数”
(j->>'x')::float AS x;
通过转换 string 解析字符串以获取“二进制 SQL 布尔值”(j->>'y')::boolean AS y。
程序员是否没有语法或优化函数来强制执行直接转换?
我在指南中没有看到 ......或者它从未实施过:它是否存在技术障碍?
关于我们需要它的典型场景的注释
(回应评论)
想象一个场景,您的系统需要以最少的磁盘使用存储许多小型数据集(真实示例!),并使用集中控制/元数据/等进行管理。JSONb 是一个很好的解决方案,并且提供了至少 2 个很好的替代方案来存储在数据库中:
- 元数据(带有模式描述符)和数组数组中的所有数据集;
- 分离两个表中的元数据和表行。
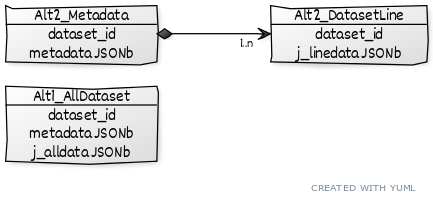
(以及将元数据转换为缓存text[]等的变体)
Alternative-1,monolitic,最适合“最小磁盘使用”要求,并且对于完整信息检索更快。Alternative-2 可以是随机访问或部分检索的选择,当表Alt2_DatasetLine也有更多一列(如时间)用于时间序列时。
例如,您可以在单独的架构中创建所有 SQL 视图
CREATE mydatasets.t1234 AS
SELECT (j->>'d')::date AS d, j->>'t' AS t, (j->>'b')::boolean AS b,
(j->>'i')::int AS i, (j->>'f')::float AS f
FROM (
select jsonb_array_elements(j_alldata) j FROM Alt1_AllDataset
where dataset_id=1234
) t
-- or FROM alt2...
;
并且 CREATE VIEW 可以全自动地动态运行 SQL 字符串......我们可以通过简单的格式化规则重现上述“稳定模式转换”,从元数据中提取:
SELECT string_agg( CASE
WHEN x[2]!='text' THEN format(E'(j->>\'%s\')::%s AS %s',x[1],x[2],x[1])
ELSE format(E'j->>\'%s\' AS %s',x[1],x[1])
END, ',' ) as x2
FROM (
SELECT regexp_split_to_array(trim(x),'\s+') x
FROM regexp_split_to_table('d date, t text, b boolean, i int, f float', ',') t1(x)
) t2;
...这是一个“现实生活场景”,这个(显然丑陋的)模型对于小流量应用程序来说速度惊人。除了磁盘使用量减少之外,还有其他优点: 灵活性(您可以更改数据集模式而无需更改 SQL 模式)和 可扩展性(2、3、... 10 亿个不同的数据集在同一张表上)。
回到问题上来:想象一个有大约 50 列或更多列的数据集,如果 PostgreSQL 提供“bynary to bynary cast”,SQL VIEW 会更快。