我想知道哪种并行策略、spark 或其他什么可以用于递归执行包含大量条件测试的 Haskell 程序。
假设一个程序有很多条件测试,递归。我想如果使用火花,那么大多数火花将在无用的分支上工作。火花生命周期不包括取消。
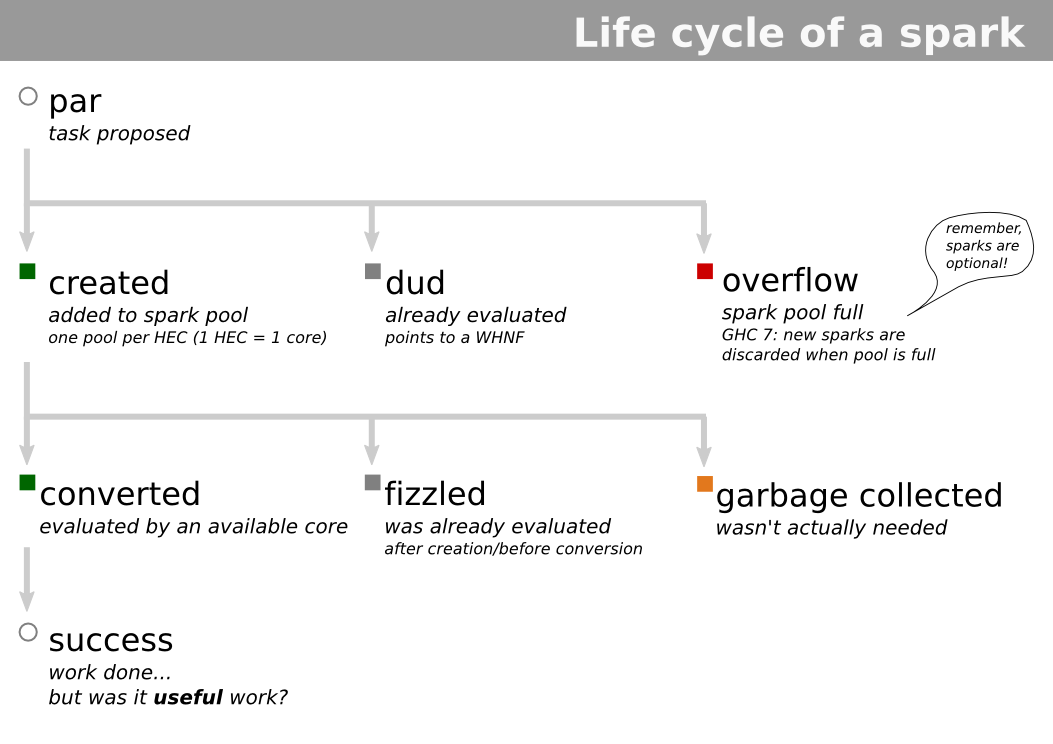{kind=link}
一个可行的策略必须能够在依赖树中有效地创建,但也可以取消工作单元。
例如,考虑解析文本的问题。解析器由一个巨大的树组成,基本上:
if <looks-like-1> then
if <looks-like 1.1> then
if <looks-like 1.1.1> then
success
else failure
else if <looks-like 1.1> ...
else if ...
在给定的条件下,我们直到很久以后才能知道我们是否会回溯。通过推测性地执行另一个分支,我们可以更快地解决这个问题。
但是,如果我们只使用火花,那么无用的工作就会呈指数级增长,而且我们不会获得太多的加速。当我们知道它永远不会被占用时,必须有一种方法可以取消已经在分支上开始的工作。
对此的概括是对实现的任何数据类型的推测执行Alternative,其想法是取消从未观察到的替代方案不会改变程序的语义。所以a <|> bwhereb不是从表达式返回的,可以短路,比如在推测执行期间抛出异常,而不影响语义。
你会如何在 Haskell 中解决这个问题?