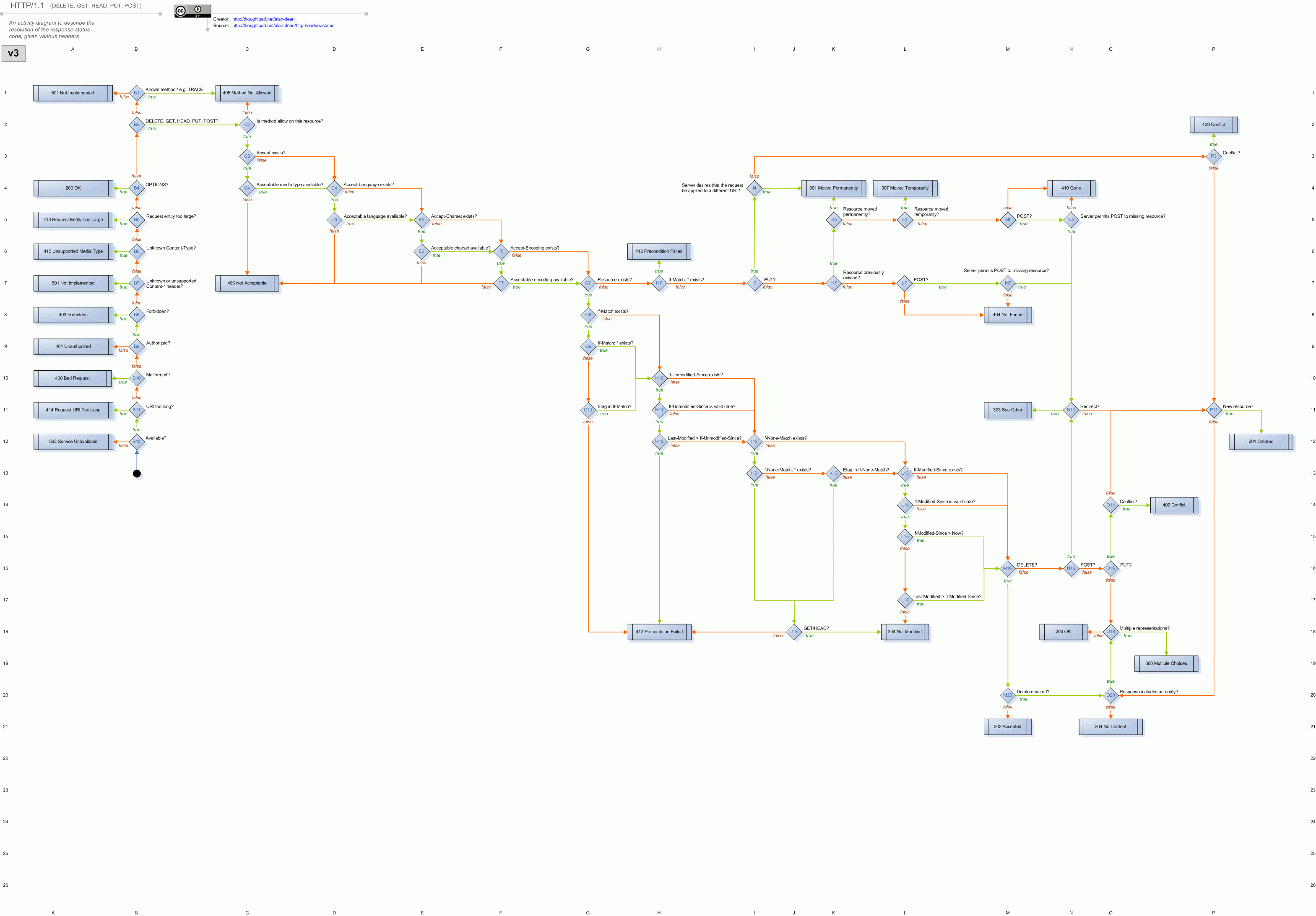
我在 kubernetes 集群中运行 nginx-ingress 控制器,我的请求日志语句之一如下所示:
upstream_response_length: 0, 840
upstream_response_time: 60.000, 0.760
upstream_status: 504, 200
我不太明白这是什么意思?Nginx 的响应超时等于 60 秒,然后尝试再请求一次(成功)并记录两个请求?
日志格式的 PS Config:
log-format-upstream: >-
{
...
"upstream_status": "$upstream_status",
"upstream_response_length": "$upstream_response_length",
"upstream_response_time": "$upstream_response_time",
...
}