对于家庭作业,我必须绘制文本的词频并将其与最佳zipf分布进行比较。
根据对数日志图中的排名绘制文本的计数词频似乎工作正常。
但是我在计算最佳 zipf 分布时遇到了麻烦。结果应如下所示:
我不明白计算直线的方程式是什么样的zipf。
在zipf法律的德国维基百科页面上,我发现了一个似乎有效的方程式

但是没有引用来源,所以我不明白常数的1.78来源。
#tokenizes the file
tokens = word_tokenize(raw)
tokensNLTK = Text(tokens)
#calculates the FreqDist of all words - all words in lower case
freq_list = FreqDist([w.lower() for w in tokensNLTK]).most_common()
#Data for X- and Y-Axis plot
values=[]
for item in (freq_list):
value = (list(item)[1]) / len([w.lower() for w in tokensNLTK])
values.append(value)
#graph of counted frequencies gets plotted
plt.yscale('log')
plt.xscale('log')
plt.plot(np.array(list(range(1, (len(values)+1)))), np.array(values))
#graph of optimal zipf distribution is plotted
optimal_zipf = 1/(np.array(list(range(1, (len(values)+1))))* np.log(1.78*len(values)))###1.78
plt.plot(np.array(list(range(1, (len(values)+1)))), optimal_zipf)
plt.show()
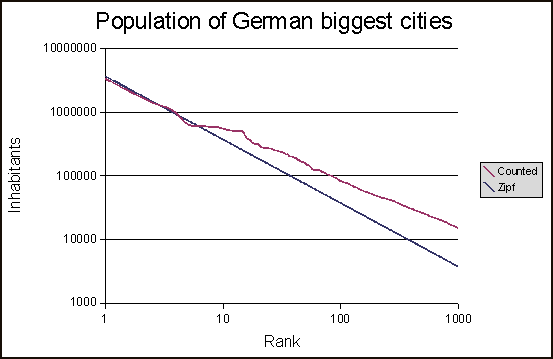
我使用此脚本的结果如下所示:

但我只是不确定最佳zipf分布是否计算正确。如果是这样,最优zipf分布不应该在某一点穿过 X 轴吗?
编辑:如果有帮助,我的文本有 2440400 个标记和 27491 种类型