GiST 索引是 B 树索引的泛化。
在B-tree index的非叶块中,两个连续的索引条目定义了这些索引条目之间指针目标处的子树中的索引值的边界:
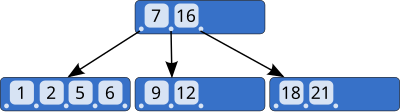
换句话说,每个指向下一个较低级别的指针都标有一个包含子树中所有值的区间。
这仅适用于具有总排序的数据类型。
GiST 索引扩展了这个概念。非叶节点中的每个条目都有一个条件,该索引条目下的子树必须满足。
扫描 GiST 索引时,我会在索引页面中搜索所有可能包含与我的搜索条件匹配的值的条目。由于没有完全排序,有可能(但当然不希望)条件以某种方式“重叠”,因此我搜索的内容可以在多个条目中匹配。在这种情况下,我必须下降到所有引用的子树,但我可以跳过那些条目的条件保证子树不能包含与我的搜索条件匹配的条目。
这有点抽象,所以让我们用一个例子来充实它。
GiST 索引的经典示例之一是R-tree索引,它是 PostGIS 使用的一种地理索引:

这里索引条目的条件是一个边界框,它包含索引条目的子树中包含的所有几何图形的边界框。因此,在搜索几何图形时,我会使用它的边界框并查看页面中的哪些索引条目包含此边界框。这些是我必须下降到的子树。
在此示例中可以看到的一件事是 GiST 索引可能是有损的,也就是说,如果我找到了命中,它会给我一个neccesary但不是充分条件。如果实际表条目也满足条件(并非每个几何图形都是矩形),则始终必须重新检查在 GiST 索引扫描中找到的叶条目。这就是为什么 GiST 索引扫描在 PostgreSQL中始终是位图索引扫描的原因。
这一切听起来很简单。一个好的 GiST 索引的难点在于picksplit 算法,它决定索引页拆分后,哪些索引条目进入两个新索引页中的哪一个。效果越好,索引的效率就越高。
所以你看,GiST 索引在很多方面都“有点像”B 树索引。您可以将 B-tree 索引视为 GiST 索引的优化特例(请参阅btree-gist contrib 模块)。
这让我回答你的问题:
GiST 叶节点还包含关键数据和有关堆元组存储位置的信息
这是真实的。
GiST 叶的键中可能包含也可能不包含整行数据
当然,索引条目不包含整行。但我认为你的意思是对的。GiST 叶中的条件可以比表中的实际对象更广泛,就像边界框比几何体大。
如果我能够将表数据的一部分存储在一个叶节点中,另一部分存储在另一个叶节点中,并使它们都指向一个堆元组,这可能吗?这将使 GiST 索引元组和堆元组之间的关系多对一。
这是错误的。即使一个值可能满足 GiST 索引页中的多个条目,它也只包含在其中一个子树中,并且只有一个叶页条目指向任何给定的表行。它是一对一的关系,就像在 B 树索引中一样。