使用正则表达式:
$ cat script.py
from __future__ import print_function
import sys, re
"""
Multiline comment with unique
text pertaining to the Foo class
"""
class Foo():
pass
"""
Multiline comment with unique
text pertaining to the Bar class
"""
class Bar():
pass
"""
Multiline comment with unique
text pertaining to the FooBar class
"""
class FooBar():
pass
def print_comments():
with open(sys.argv[0]) as f:
file_contents = f.read()
map(print, re.findall(r'"""\n([^"""]*)"""', file_contents, re.S))
print_comments()
$ python script.py
Multiline comment with unique
text pertaining to the Foo class
Multiline comment with unique
text pertaining to the Bar class
Multiline comment with unique
text pertaining to the FooBar class
正则表达式解释:
"""\n([^"""]*)"""
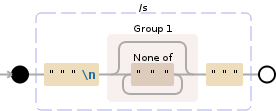
调试演示
理想的方法是使用 ast 模块,解析整个文档,然后在 ast.FunctionDef、ast.ClassDef 或 ast.Module 类型的所有节点上打印调用 ast.get_docstring。但是,您的评论不是文档字符串。如果文件是这样的:
$ cat script.py
import sys, re, ast
class Foo():
"""
Multiline comment with unique
text pertaining to the Foo class
"""
pass
class Bar():
"""
Multiline comment with unique
text pertaining to the Bar class
"""
pass
class FooBar():
"""
Multiline comment with unique
text pertaining to the FooBar class
"""
pass
def print_docstrings():
with open(sys.argv[0]) as f:
file_contents = f.read()
tree = ast.parse(file_contents)
class_nodes = filter((lambda x: type(x) in [ast.ClassDef, ast.FunctionDef, ast.Module]), ast.walk(tree))
for node in class_nodes:
doc_str = ast.get_docstring(node)
if doc_str:
print doc_str
print_docstrings()
$ python script.py
Multiline comment with unique
text pertaining to the Foo class
Multiline comment with unique
text pertaining to the Bar class
Multiline comment with unique
text pertaining to the FooBar class