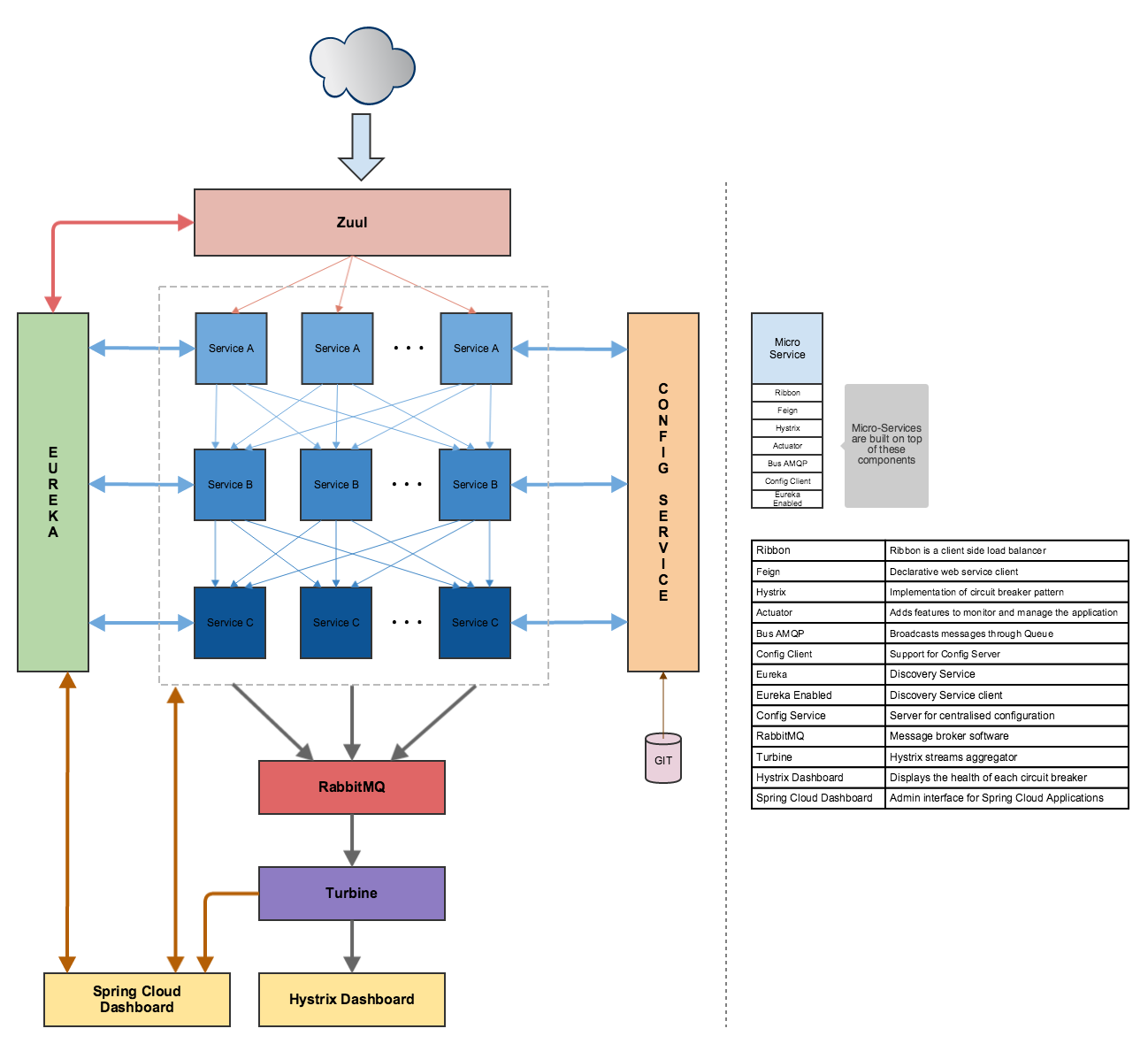
我正在尝试一种非常类似于此处图片中详细说明的设置:https ://raw.githubusercontent.com/Oreste-Luci/netflix-oss-example/master/netflix-oss-example.png
{kind=link}
在我的设置中,我使用了一个客户端应用程序 ( https://www.joedog.org/siege-home/ )、一个代理 (Zuul)、一个发现服务 (Eureka) 和一个简单的微服务。一切都部署在 PWS 上。
我想在不停机的情况下从我的简单微服务的一个版本迁移到下一个版本。最初,我从这里描述的技术开始:https ://docs.cloudfoundry.org/devguide/deploy-apps/blue-green.html
在我看来,这种方法与 Eureka 等发现服务不“兼容”。事实上,我的服务的新版本已在 Eureka 中注册,甚至在我重新映射所有路由(CF 路由器)之前就已接收流量。
这导致我采用另一种方法,其中我依赖 Spring Cloud/Netflix 中的故障转移机制:
- 我启动了我的服务的新(向后兼容)版本。
- 当这个版本被 Zuul/Eureka 选中时,它开始获得 50% 的流量。
- 一旦我确认新版本可以正常工作,我就会删除“旧”实例。(我只需点击 PWS 中的“停止”按钮)
据我了解,Zuul 在后台使用 Ribbon(负载平衡),因此在旧实例仍在 Eureka 但实际上正在关闭的那一瞬间,我希望重试新实例,而不会对客户端产生任何影响。
然而,我的假设是错误的。我的客户端出现了一些 502 错误:
Lifting the server siege... done.
Transactions: 5305 hits
Availability: 99.96 %
Elapsed time: 59.61 secs
Data transferred: 26.06 MB
Response time: 0.17 secs
Transaction rate: 89.00 trans/sec
Throughput: 0.44 MB/sec
Concurrency: 14.96
Successful transactions: 5305
Failed transactions: 2
Longest transaction: 3.17
Shortest transaction: 0.14
我的 application.yml 的一部分
server:
port: ${PORT:8765}
info:
component: proxy
ribbon:
MaxAutoRetries: 2 # Max number of retries on the same server (excluding the first try)
MaxAutoRetriesNextServer: 2 # Max number of next servers to retry (excluding the first server)
OkToRetryOnAllOperations: true # Whether all operations can be retried for this client
ServerListRefreshInterval: 2000 # Interval to refresh the server list from the source
ConnectTimeout: 3000 # Connect timeout used by Apache HttpClient
ReadTimeout: 3000 # Read timeout used by Apache HttpClient
hystrix:
threadpool:
default:
coreSize: 50
maxQueueSize: 100
queueSizeRejectionThreshold: 50
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 10000
我不确定出了什么问题。
这是技术问题吗?
还是我做出了错误的假设(我确实在某处读到过 POST 无论如何都不会重试,我不太明白)?
我很想听听你是怎么做到的。
谢谢,安迪