我试图排除一组单词,但在 qregexp 表达式中包含另一组单词,但我目前在解决这个问题时遇到了问题。
以下是我尝试过的一些事情(这个例子包括了所有的单词):
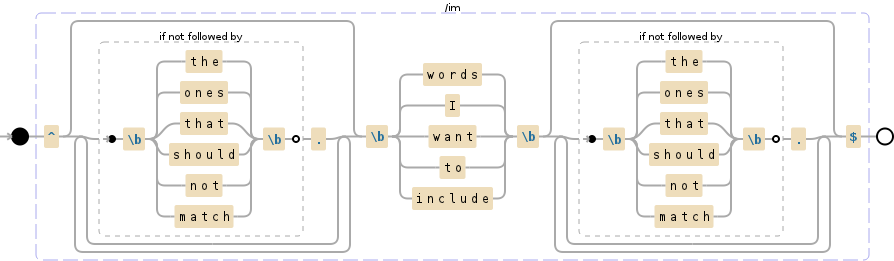
(words|I|want|to|include)(?!the|ones|that|should|not|match)
所以我尝试了这个(它什么也没返回):
^(words|I|want|to|include)(?:(?!the|ones|that|should|not|match).)*$
我错过了什么吗?
编辑:我需要这样一个不寻常的正则表达式(包含/排除)的原因是因为我想搜索一系列文章并过滤其中包含包含单词的文章,但如果它们也包含排除单词则不过滤。
例如,如果文章 A 是:
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
B条是:
Vivamus fermentum semper porta.
然后包含的正则表达式lorem将过滤文章 A 而不是 B。但如果ipsum是我排除的单词,我不希望文章 A 被过滤。
我考虑做一个正则表达式来过滤出我想要的单词的文章,然后运行第二个正则表达式,排除第一组我不想要的文章,但不幸的是我使用的软件不允许我这样做。我只能运行一个正则表达式。