给定一个单词字典和一个初始字符。通过连续添加一个字符来找到字典中可能最长的单词。在任何给定的情况下,该词都应该是字典中的有效词。
例如:a -> at -> cat -> cart -> chart ....
给定一个单词字典和一个初始字符。通过连续添加一个字符来找到字典中可能最长的单词。在任何给定的情况下,该词都应该是字典中的有效词。
例如:a -> at -> cat -> cart -> chart ....
蛮力方法是尝试使用深度优先搜索向每个可用索引添加字母。
因此,从“a”开始,您可以在两个地方添加新字母。在“a”的前面或后面,用下面的点表示。
.a.
如果添加“t”,则现在有三个位置。
.a.t.
您可以尝试将所有 26 个字母添加到每个可用位置。在这种情况下,字典可以是一个简单的哈希表。如果你在中间添加一个“z”,你会得到一个不在哈希表中的“azt”,所以你不会在搜索中继续沿着这条路径前进。
编辑:尼克约翰逊的图表让我很好奇所有最大路径的图表是什么样的。这是一个大 (1.6 MB) 图像:
http://www.michaelfogleman.com/static/images/word_graph.png
编辑:这是一个 Python 实现。蛮力方法实际上在合理的时间内运行(几秒钟,取决于起始字母)。
import heapq
letters = 'abcdefghijklmnopqrstuvwxyz'
def search(words, word, path):
path.append(word)
yield tuple(path)
for i in xrange(len(word)+1):
before, after = word[:i], word[i:]
for c in letters:
new_word = '%s%s%s' % (before, c, after)
if new_word in words:
for new_path in search(words, new_word, path):
yield new_path
path.pop()
def load(path):
result = set()
with open(path, 'r') as f:
for line in f:
word = line.lower().strip()
result.add(word)
return result
def find_top(paths, n):
gen = ((len(x), x) for x in paths)
return heapq.nlargest(n, gen)
if __name__ == '__main__':
words = load('TWL06.txt')
gen = search(words, 'b', [])
top = find_top(gen, 10)
for path in top:
print path
当然,答案中会有很多联系。这将打印前 N 个结果,以最终单词的长度来衡量。
使用 TWL06 Scrabble 字典的起始字母“a”的输出。
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampeder', 'stampeders'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'estranges', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangers', 'stranglers'))
这是每个起始字母的结果。当然,一个例外是单个起始字母不必在字典中。只是一些可以用它组成的两个字母的单词。
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(9, ('b', 'bo', 'bos', 'bods', 'bodes', 'bodies', 'boodies', 'bloodies', 'bloodiest'))
(1, ('c',))
(10, ('d', 'od', 'cod', 'coed', 'coped', 'comped', 'compted', 'competed', 'completed', 'complected'))
(10, ('e', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(9, ('f', 'fe', 'foe', 'fore', 'forge', 'forges', 'forgoes', 'forgoers', 'foregoers'))
(10, ('g', 'ag', 'tag', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(9, ('h', 'sh', 'she', 'shes', 'ashes', 'sashes', 'slashes', 'splashes', 'splashers'))
(11, ('i', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(7, ('j', 'jo', 'joy', 'joky', 'jokey', 'jockey', 'jockeys'))
(9, ('k', 'ki', 'kin', 'akin', 'takin', 'takins', 'takings', 'talkings', 'stalkings'))
(10, ('l', 'la', 'las', 'lass', 'lassi', 'lassis', 'lassies', 'glassies', 'glassines', 'glassiness'))
(10, ('m', 'ma', 'mas', 'mars', 'maras', 'madras', 'madrasa', 'madrassa', 'madrassas', 'madrassahs'))
(11, ('n', 'in', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(10, ('o', 'os', 'ose', 'rose', 'rouse', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(11, ('p', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(3, ('q', 'qi', 'qis'))
(10, ('r', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('s', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('t', 'ti', 'tin', 'ting', 'sting', 'sating', 'stating', 'estating', 'restating', 'restarting'))
(10, ('u', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(1, ('v',))
(9, ('w', 'we', 'wae', 'wake', 'wakes', 'wackes', 'wackest', 'wackiest', 'whackiest'))
(8, ('x', 'ax', 'max', 'maxi', 'maxim', 'maxima', 'maximal', 'maximals'))
(8, ('y', 'ye', 'tye', 'stye', 'styed', 'stayed', 'strayed', 'estrayed'))
(8, ('z', 'za', 'zoa', 'zona', 'zonae', 'zonate', 'zonated', 'ozonated'))
如果您想这样做一次,我会执行以下操作(概括为以完整单词开头的问题):
拿走你的整个字典,扔掉目标词中没有字符超集的任何东西(假设它有 length m)。然后将剩余的单词按长度分箱。对于 length 的每个单词m+1,尝试删除每个字母,看看是否会产生您想要的单词。如果没有,扔掉它。然后m+2根据有效的长度集检查长度的每个单词m+1,删除任何不能减少的单词。继续前进,直到找到一个空集;您找到的最后一件事将是最长的。
如果您想快速查找,我会构建一个类似后缀树的数据结构。
按长度对所有单词进行分组。对于每个长度为 2 的单词,将其两个字符中的每一个放入“子词”集中,并将该词添加到每个字符的“超词”集中。现在您已经在长度为 2 的所有有效单词和所有字符之间建立了一个链接。对长度为 3 的单词和长度为 2 的有效单词执行相同的操作。现在您可以从该层次结构中的任何位置开始,进行广度优先搜索以找到最深的分支。
编辑:这个解决方案的速度将很大程度上取决于语言的结构,但是如果我们决定使用具有log(n)所有操作性能的集合来构建所有东西(即我们使用红黑树等),并且我们有N(m)长度的单词m,然后形成长度m+1和m将近似(m+1)*m*N(m+1)*log(N(m))时间的单词之间的联系(考虑到字符串比较在字符串长度上花费线性时间)。由于我们必须对所有字长执行此操作,因此构建完整数据结构的运行时间大约为
(typical word length)^3 * (dictionary length) * log (dictionary length / word length)
(初始分箱到一定长度的单词将花费线性时间,因此可以忽略;运行时的实际公式很复杂,因为它取决于单词长度的分布;对于您从单个单词进行的情况,它是甚至更复杂,因为它取决于具有较短子词的较长词的预期数量。)
假设您需要重复执行此操作(或者您想要 26 个字母中的每一个的答案),请向后执行:
然后,要获取给定前缀的链,只需从该前缀开始并在字典中反复查找它及其扩展。
这是示例 Python 代码:
words = [x.strip().lower() for x in open('/usr/share/dict/words')]
words.sort(key=lambda x:len(x), reverse=True)
word_map = {} # Maps words to (extension, max_len) tuples
for word in words:
if word in word_map:
max_len = word_map[word][1]
else:
max_len = len(word)
for i in range(len(word)):
new_word = word[:i] + word[i+1:]
if new_word not in word_map or word_map[new_word][2] < max_len:
word_map[new_word] = (word, max_len)
# Get a chain for each letter
for term in "abcdefghijklmnopqrstuvwxyz":
chain = [term]
while term in word_map:
term = word_map[term][0]
chain.append(term)
print chain
以及它对字母表中每个字母的输出:
['a', 'ah', 'bah', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['b', 'ba', 'bac', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['c', 'ca', 'cap', 'camp', 'campo', 'campho', 'camphor', 'camphory', 'camphoryl', 'camphoroyl']
['d', 'ad', 'cad', 'card', 'carid', 'carida', 'caridea', 'acaridea', 'acaridean']
['e', 'er', 'ser', 'sere', 'secre', 'secret', 'secreto', 'secretor', 'secretory', 'asecretory']
['f', 'fo', 'fot', 'frot', 'front', 'afront', 'affront', 'affronte', 'affronted']
['g', 'og', 'log', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['h', 'ah', 'bah', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['i', 'ai', 'lai', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['j', 'ju', 'jug', 'juga', 'jugal', 'jugale']
['k', 'ak', 'sak', 'sake', 'stake', 'strake', 'straked', 'streaked']
['l', 'la', 'lai', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['m', 'am', 'cam', 'camp', 'campo', 'campho', 'camphor', 'camphory', 'camphoryl', 'camphoroyl']
['n', 'an', 'lan', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['o', 'lo', 'loy', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['p', 'pi', 'pig', 'prig', 'sprig', 'spring', 'springy', 'springly', 'sparingly', 'sparringly']
['q']
['r', 'ra', 'rah', 'rach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['s', 'si', 'sig', 'spig', 'sprig', 'spring', 'springy', 'springly', 'sparingly', 'sparringly']
['t', 'ut', 'gut', 'gutt', 'gutte', 'guttle', 'guttule', 'guttulae', 'guttulate', 'eguttulate']
['u', 'ut', 'gut', 'gutt', 'gutte', 'guttle', 'guttule', 'guttulae', 'guttulate', 'eguttulate']
['v', 'vu', 'vum', 'ovum']
['w', 'ow', 'low', 'alow', 'allow', 'hallow', 'shallow', 'shallowy', 'shallowly']
['x', 'ox', 'cox', 'coxa', 'coxal', 'coaxal', 'coaxial', 'conaxial']
['y', 'ly', 'loy', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['z', 'za', 'zar', 'izar', 'izard', 'izzard', 'gizzard']
编辑:鉴于分支最终合并的程度,我认为绘制图表来证明这一点会很有趣:
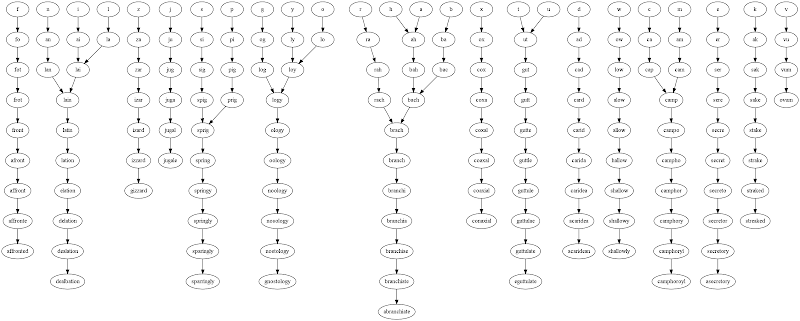
这个挑战的一个有趣的扩展:一些字母可能有几个等长的词尾。哪一组链最小化最终节点的数量(例如,合并最多的字母)?
{kind=link}