我试图找到一种空间要求适中的快速算法来解决以下问题。
对于 DAG 的每个顶点,在 DAG 的传递闭包中找到其入度和出度的总和。
鉴于此 DAG:
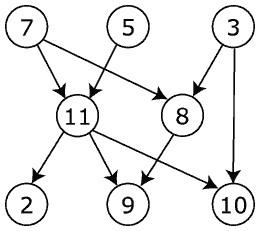
我期待以下结果:
Vertex # Reacability Count Reachable Vertices in closure
7 5 (11, 8, 2, 9, 10)
5 4 (11, 2, 9, 10)
3 3 (8, 9, 10)
11 5 (7, 5, 2, 9, 10)
8 3 (7, 3, 9)
2 3 (7, 5, 11)
9 5 (7, 5, 11, 8, 3)
10 4 (7, 5, 11, 3)
在我看来,这应该是可能的,而无需实际构建传递闭包。我无法在网上找到任何能准确描述这个问题的东西。我有一些关于如何做到这一点的想法,但我想看看 SO 人群能想出什么。