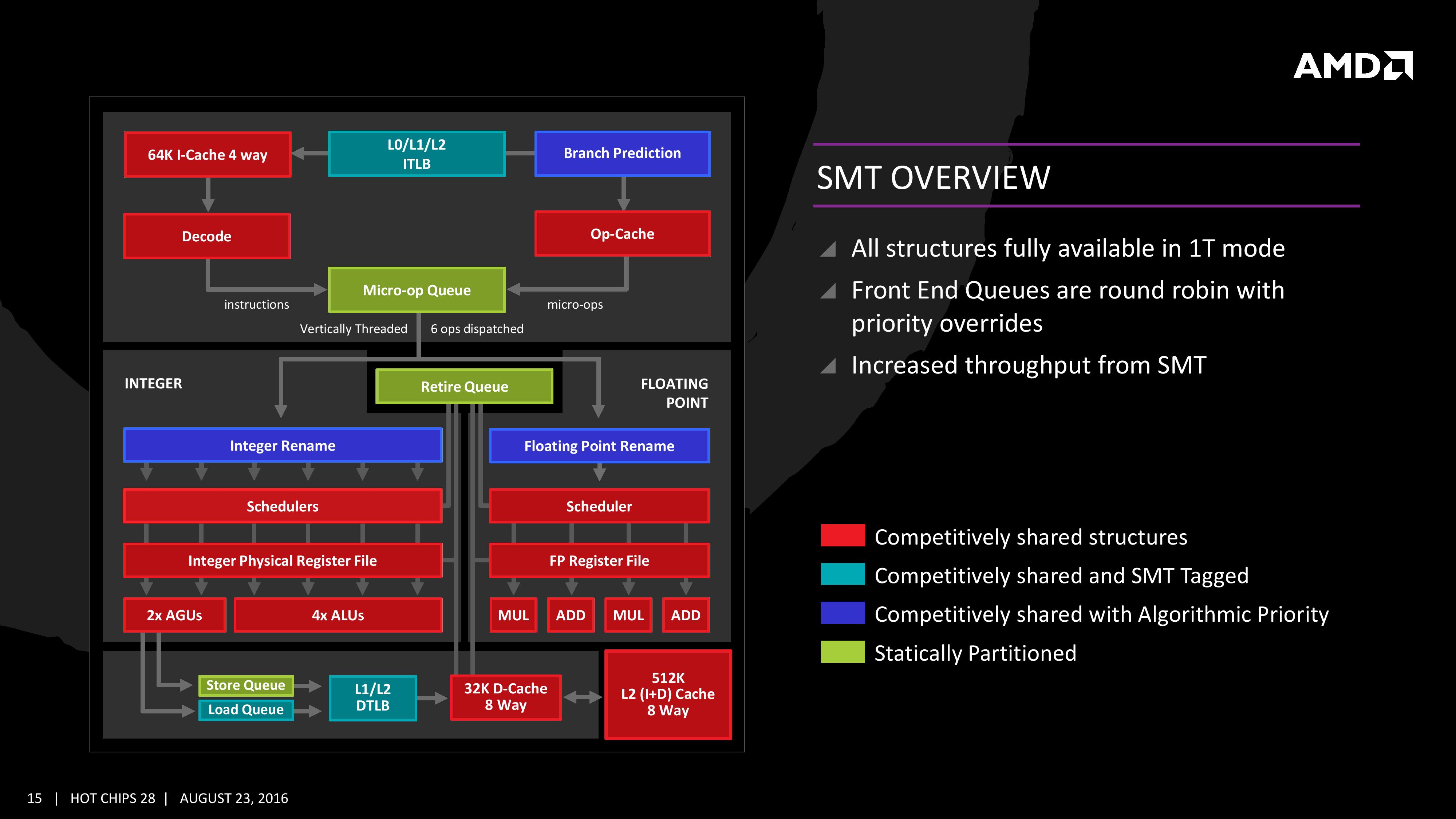
超线程是否有帮助以及在多大程度上取决于线程在做什么。这不仅仅是在一个线程中工作,而另一个线程等待 I/O 或缓存未命中 - 尽管这是基本原理的重要组成部分。它是关于有效地使用 CPU 资源来增加总系统吞吐量。假设你有两个线程
- 一个有很多数据缓存未命中(空间局部性差)并且不使用浮点,空间局部性差不一定是程序员做得不好,有些工作负载天生就是这样。
- 另一个线程正在从内存中流式传输数据并进行浮点计算
使用超线程,这两个线程可以共享同一个 CPU,一个是执行整数运算并获取缓存未命中和停顿,另一个是使用浮点单元,数据预取器可以提前预测来自内存的顺序数据。系统吞吐量优于操作系统在同一个 CPU 内核上交替调度两个线程的情况。
英特尔选择不在 Silvermont 中包含超线程,但这并不意味着它将在高端 Xeon 服务器处理器甚至针对笔记本电脑的处理器中取消它。为处理器选择微架构涉及权衡,有很多考虑因素:
- 目标市场是什么(将运行什么样的应用程序)?
- 目标晶体管技术是什么?
- 绩效目标是什么?
- 什么是功率预算?
- 目标芯片尺寸是多少(影响良率)?
- 它在公司未来产品的性价比范围内处于什么位置?
- 目标发布日期是什么时候?
- 有多少资源可用于实施和验证设计?添加微架构功能会增加非线性的复杂性,与其他功能存在微妙的交互,目标是在第一次“流片”之前识别尽可能多的错误,以最大限度地减少必须完成的“步进”次数一个工作芯片。
Silvermont 的每个内核的裸片尺寸预算和功率预算排除了乱序执行和超线程,而乱序执行提供了更好的单线程性能。 这是 Anandtech 的评估:
如果我不得不用 Silvermont 来描述英特尔的设计理念,那将是明智的扩展。我们已经从 Apple 的 Swift 以及从 Qualcomm 的 Krait 200 到 Krait 300 的过渡中看到了这一点。请记住最初 Atom 的设计规则:性能每提高 2%,Atom 架构师最多可以将功率提高 1%。换句话说,性能可以提高,但每瓦性能不能下降。Silvermont 坚持这种设计理念,我想我知道如何去做。
以前版本的 Atom 使用超线程来很好地利用执行资源。超线程有与之相关的功率损失,但性能提升足以证明它是合理的。在 22nm 时,英特尔有足够的裸片面积(得益于晶体管缩放)来添加更多内核,而不是依赖 HT 来获得更好的线程性能,因此超线程已被淘汰。英特尔从摆脱超线程中获得的电力节省随后被分配用于使 Silvermont 成为无序设计,这反过来又有助于在没有 HT 的情况下提高执行资源的有效使用。事实证明,在 22nm 时,英特尔用于启用 HT 的芯片面积与 Silvermont 的重新排序缓冲区和 OoO 逻辑大致相同,因此这一举动甚至没有面积损失。