DataFrame外推Pandas
DataFrames 可以推断,但是,pandas 中没有简单的方法调用,需要另一个库(例如scipy.optimize)。
外推
一般来说,外推需要对被外推的数据做出某些假设。一种方法是通过对数据进行曲线拟合一些通用参数化方程来找到最能描述现有数据的参数值,然后将其用于计算超出该数据范围的值。这种方法的困难和限制问题是关于趋势的一些假设必须在选择参数化方程时进行。这可以通过使用不同方程式的反复试验来找到,以获得所需的结果,或者有时可以从数据源中推断出来。问题中提供的数据确实没有足够大的数据集来获得拟合曲线;但是,它足以说明。
以下是DataFrame使用 3阶多项式外推 的示例
f ( x ) = a x 3 + b x 2 + c x + d (等式 1)
该通用函数 ( func()) 对每一列进行曲线拟合,以获得独特的列特定参数(即a、b、c、d)。然后这些参数化方程用于外推每列中所有带有NaNs 的索引的数据。
import pandas as pd
from cStringIO import StringIO
from scipy.optimize import curve_fit
df = pd.read_table(StringIO('''
neg neu pos avg
0 NaN NaN NaN NaN
250 0.508475 0.527027 0.641292 0.558931
500 NaN NaN NaN NaN
1000 0.650000 0.571429 0.653983 0.625137
2000 NaN NaN NaN NaN
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN'''), sep='\s+')
# Do the original interpolation
df.interpolate(method='nearest', xis=0, inplace=True)
# Display result
print ('Interpolated data:')
print (df)
print ()
# Function to curve fit to the data
def func(x, a, b, c, d):
return a * (x ** 3) + b * (x ** 2) + c * x + d
# Initial parameter guess, just to kick off the optimization
guess = (0.5, 0.5, 0.5, 0.5)
# Create copy of data to remove NaNs for curve fitting
fit_df = df.dropna()
# Place to store function parameters for each column
col_params = {}
# Curve fit each column
for col in fit_df.columns:
# Get x & y
x = fit_df.index.astype(float).values
y = fit_df[col].values
# Curve fit column and get curve parameters
params = curve_fit(func, x, y, guess)
# Store optimized parameters
col_params[col] = params[0]
# Extrapolate each column
for col in df.columns:
# Get the index values for NaNs in the column
x = df[pd.isnull(df[col])].index.astype(float).values
# Extrapolate those points with the fitted function
df[col][x] = func(x, *col_params[col])
# Display result
print ('Extrapolated data:')
print (df)
print ()
print ('Data was extrapolated with these column functions:')
for col in col_params:
print ('f_{}(x) = {:0.3e} x^3 + {:0.3e} x^2 + {:0.4f} x + {:0.4f}'.format(col, *col_params[col]))
外推结果
Interpolated data:
neg neu pos avg
0 NaN NaN NaN NaN
250 0.508475 0.527027 0.641292 0.558931
500 0.508475 0.527027 0.641292 0.558931
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN
Extrapolated data:
neg neu pos avg
0 0.411206 0.486983 0.631233 0.509807
250 0.508475 0.527027 0.641292 0.558931
500 0.508475 0.527027 0.641292 0.558931
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 0.621036 0.969232 0.708464 0.766245
6000 1.197762 2.799529 0.991552 1.662954
8000 3.281869 7.191776 1.702860 4.058855
10000 7.767992 15.272849 3.041316 8.694096
20000 97.540944 150.451269 26.103320 91.365599
30000 381.559069 546.881749 94.683310 341.042883
50000 1979.646859 2686.936912 467.861511 1711.489069
Data was extrapolated with these column functions:
f_neg(x) = 1.864e-11 x^3 + -1.471e-07 x^2 + 0.0003 x + 0.4112
f_neu(x) = 2.348e-11 x^3 + -1.023e-07 x^2 + 0.0002 x + 0.4870
f_avg(x) = 1.542e-11 x^3 + -9.016e-08 x^2 + 0.0002 x + 0.5098
f_pos(x) = 4.144e-12 x^3 + -2.107e-08 x^2 + 0.0000 x + 0.6312
avg列图
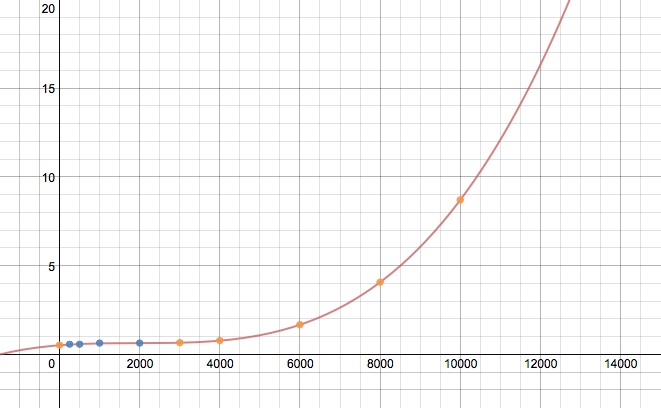
如果没有更大的数据集或不知道数据的来源,这个结果可能完全错误,但应该举例说明推断 a 的过程DataFrame。func()可能需要使用假设的方程来获得正确的外推。此外,没有尝试使代码高效。
更新:
如果您的索引是非数字的,例如 a DatetimeIndex,请参阅此答案以了解如何推断它们。