用例是自动完成选项,我想根据它们与固定字符串的相似程度对大量其他字符串进行排名。
是否有任何像 DFA RegEx 这样的混蛋可以比重新开始每个选项解决方案做得更好?
问这个问题的人似乎知道解决方案,但没有列出任何来源。
(ps“阅读此链接”类型回答欢迎。)
用例是自动完成选项,我想根据它们与固定字符串的相似程度对大量其他字符串进行排名。
是否有任何像 DFA RegEx 这样的混蛋可以比重新开始每个选项解决方案做得更好?
问这个问题的人似乎知道解决方案,但没有列出任何来源。
(ps“阅读此链接”类型回答欢迎。)
我最近做了这样的事情。不幸的是,它是封闭源代码。
解决方案是编写一个levenshtein automaton。剧透:这是一个NFA。
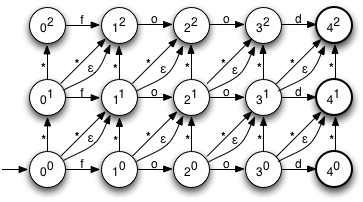
尽管许多人会试图说服您模拟 NFA 是指数级的,但事实并非如此。从 NFA 创建 DFA 是指数级的。模拟只是多项式。许多正则表达式引擎都是使用基于此的次优算法编写的。
对于 n 大小的字符串和 m 个状态,NFA 模拟是 O(n*m)。或者如果您将其延迟转换为 DFA(并缓存它),则 O(n) 摊销。
恐怕您要么必须处理复杂的自动机库,要么必须编写大量代码(我所做的)。