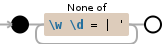我很难得到这个。。
我有这个 html 代码:
<table border='1'><tr><th></th><th>Fact Questions Report Type Count</th></tr><tr>
<td class=' sorting_1'>0 - 18</td><td>78</td></tr><tr><td class=' sorting_1'>19-64</td>
<td>78</td></tr><tr><td class=' sorting_1'>65+</td><td>78</td></tr><tr>
<td class=' sorting_1'>אין גיל</td><td>78</td></tr><tr><td class=' sorting_1'>נפטר</td>
<td>78</td></tr><tr><td class=' sorting_1'>Unknown</td><td>78</td></tr></table>
如您所见,我想捕捉一些特殊字符:
אין גיל,נפטר
我想做一个正则表达式,它将排除所有单词\W和数字\D以及那些->=|'
但我无法让它工作..
完美的解决方案是获得两个带有特殊字符的物品...... אין גיל,נפטר
PS:可能还有其他特殊角色
我很乐意在这里看到一个例子:RegexPal - 在线编辑器
天呐!