谁能帮助我更接近我想要得到的结果?
扫描图像后,我将此字符串作为 OCR 结果返回:
7915-03226E3058-089179 祝您在 2013 年 9 月 4 日星期三抽奖好运 您的号码 A06 09 26 40 43 45 B 06 14 18 28 43 48 C 02 16 22 34 39 42 1111111 II 1111111113 E = 1111110 110 英镑 x 11 抽奖。上周 3.00,乐透有超过 700,000 名中奖者!7915-032268058-089179 013779 期限。46377201 E - •我填写此框以使票无效
我正在尝试提取值"A06 09 26 40 43 45","B 06 14 18 28 43 48"和"C 02 16 22 34 39 42"
老实说,我不需要"A","B"和"C". 我只需要每个数字后面的 12 个数字。
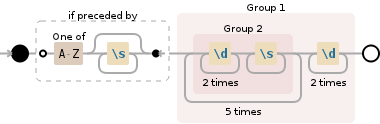
我有正则表达式
[A-Z](\W*\d{2}){6}
但这会提取我不想要的额外信息,如下所示:http ://regexr.com?372b7
谁能建议如何靠近?有没有更好的方法来尝试获取票号?