在第 1 章中Introducing regular expression,我看到了这样的正则表达式:
^(\(\d{3}\)|^\d{3}[.-]?)?\d{3}[.-]?\d{4}$

我对此有点困惑,因为第二个^对我来说似乎是多余的。|分隔两个选项\(\d{3}\)或在^\d{3}[.-]?括号内,并且括号外有 aleady a ^,我理解为匹配行首,所以我认为第二个^in^\d{3}[.-]?没有必要匹配行首。有人对此有想法吗?
在第 1 章中Introducing regular expression,我看到了这样的正则表达式:
^(\(\d{3}\)|^\d{3}[.-]?)?\d{3}[.-]?\d{4}$
我对此有点困惑,因为第二个^对我来说似乎是多余的。|分隔两个选项\(\d{3}\)或在^\d{3}[.-]?括号内,并且括号外有 aleady a ^,我理解为匹配行首,所以我认为第二个^in^\d{3}[.-]?没有必要匹配行首。有人对此有想法吗?
它看起来确实是多余的,但有一种可能的解释是有效的(尽管考虑到上下文是无意义的)。
您只在问题中包含了正则表达式模式;您没有向我们展示的是是否使用了任何修饰符。
如果您使用m修饰符将正则表达式解析器切换到多行模式,则^和$锚点会改变它们的含义,以便它们匹配一行的开始和结束,以及整个字符串。
因此,如果您的表达式正在使用m修饰符,则附加^项会告诉它在该特定实例中查找额外的换行符。所以它会对表达产生影响。
但最终,看看你引用的表达实际上是做什么的,我怀疑这是否是预期的;正如您所假设的,它看起来好像基本上是一个错误。
是的,它对我来说也是多余的。第一个锚就足够了。
以下是我认为分解成部分的方式:
^
(
\(\d{3}\)
|
^\d{3}[.-]?
)?
\d{3}
[.-]?
\d{4}
$
是的,它在那里是多余的和无用的。好吧,它不会崩溃;)
^(\(\d{3}\)|^\d{3}[.-]?)?\d{3}[.-]?\d{4}$
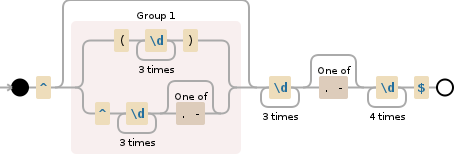
标记字符串/行^开始并且不会创建任何结果,并且内部指针也不会移动,因此表达式^, ^^or^^^^^^^都是相等的。