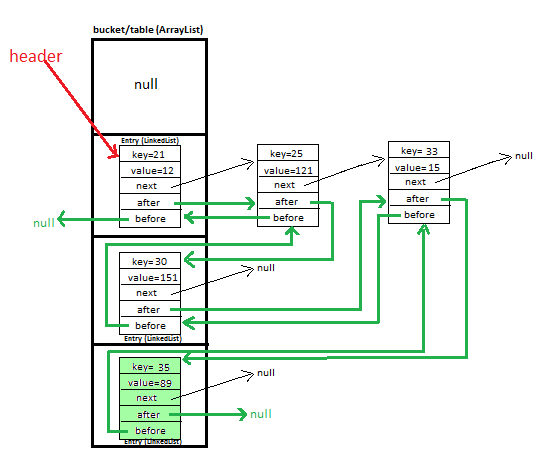
我读到 HashMap 具有以下实现:
main array
↓
[Entry] → Entry → Entry ← linked-list implementation
[Entry]
[Entry] → Entry
[Entry]
[null ]
因此,它有一个 Entry 对象数组。
问题:
我想知道这个数组的索引如何在 hashCode 相同但对象不同的情况下存储多个 Entry 对象。
这与
LinkedHashMap实施有何不同?它的 map 的双向链表实现,但它是否像上面一样维护一个数组,它如何存储指向下一个和前一个元素的指针?