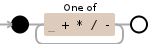Are you trying to parse your string? My guess would be you are trying to perform lexical analysis (scanning) of an input stream.
- You could hand-roll a scanner by building strtok, and character lookahead/pushback.
- You could use a took like lex, or flex to build a lexical scanner
- You could a series of regular expressions and case statements for a poor mans parser
Suppose you do want to tokenize your algebraic string. You need to define a grammar and what tokens you want to recognize. You need something like BNF (Backus-Naur Formalism), or you could use 'railroad syntax diagrams' (personally, I prefer BNF, but some people like railroad diagrams).
Here is a start:
expression --> sexpr | nil
parenexpr --> '(' sexpr ')'
sexpr --> parenexpr | addexpr | thing | nil
addexpr --> mulexpr addop mulexpr | mulexpr
mulexpr --> parenexpr
thing --> symbol | integer | real | scientific
integer --> { '+' | '-' }? digit+
real --> { '+' | '-' }? digit+ { . digit+ }?
scientific --> { + | - }? digit+ { . digit+ } e { '+' | '-' }? digit+
addop --> '+' | '-'
mulop --> '/' | '*' | '^' | '%'
relop --> '||' | '&&' | '!'
symbol --> { character | '_' } { character | '_' | digit }*
digit --> [0-9]
character --> [A-Za-z]
//etc
这意味着,语法产生符号 (-->) 左侧的每一项都扩展为右侧的一项。请注意,此定义是递归的,它可以让您了解所需的编程类型。无论如何,您将需要扫描并识别每个令牌以收集整数、实数、科学、符号、addop、mulop、relop 以及您想要提取的任何其他令牌。在此过程中,您需要决定如何处理空格(制表符、空格、换行符)和其他未定义的符号。