内部如何HashMap实现?我在某个地方读到它使用的地方,LinkedList而在其他地方它提到了数组。
我尝试研究代码HashSet并找到Entry数组。那么LinkedList用在什么地方呢?
内部如何HashMap实现?我在某个地方读到它使用的地方,LinkedList而在其他地方它提到了数组。
我尝试研究代码HashSet并找到Entry数组。那么LinkedList用在什么地方呢?
它基本上看起来像这样:
this is the main array
↓
[Entry] → Entry → Entry ← here is the linked-list
[Entry]
[Entry] → Entry
[Entry]
[null ]
[null ]
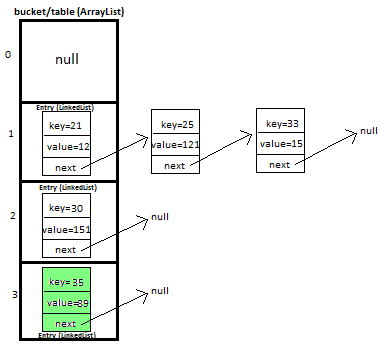
所以你有一个主数组,其中每个索引对应于一些哈希值(mod'ed* 到数组的大小)。
然后它们中的每一个都将指向具有相同哈希值的下一个条目(再次mod'ed *)。这就是链表的用武之地。
*:作为技术说明,它在被 'ed 之前首先使用不同的函数进行哈希处理mod,但是,作为基本实现,只需修改即可。
每个HashMap都有一个数组,并且在该数组中,它Entry根据其键的哈希码(例如int position = entry.getKey().hashCode() % array.length)将每个放置在一个位置。存储an 的位置Entry称为存储桶。
如果多个Entry条目最终在同一个存储桶中,则这些条目将组合在一个中LinkedList(另请参阅@Dukeling 的答案)。因此,桶隐喻:每个数组索引都是一个“桶”,您可以在其中转储所有匹配的键。
您必须为存储桶使用数组,以实现随机访问所需的恒定时间性能。在存储桶中,您必须遍历所有元素才能找到所需的密钥,因此您可以使用 aLinkedList因为它更容易附加(无需调整大小)。
这也表明需要一个好的散列函数,因为如果所有键只散列到几个值,您将获得 long LinkedLists 来搜索和大量(快速访问)空桶。
HashMap 有一个 HashMap.Entry 对象数组:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table;
我们可以说Entry 是一个单向链表(这种HashMap.Entry 链接被称为“Bucket”)但它实际上并不是一个java.util.LinkedList。
你自己看 :
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
HashMap 内部使用 Entry 来存储键值对。条目是 LinkedList 类型。
条目包含以下 ->
K键,
V 值和
条目下一个> 即存储桶该位置的下一个条目。
static class Entry<K, V> {
K key;
V value;
Entry<K,V> next;
public Entry(K key, V value, Entry<K,V> next){
this.key = key;
this.value = value;
this.next = next;
}
}
HashMap图——
来自:http ://www.javamadesoeasy.com/2015/02/hashmap-custom-implementation.html
映射是基于键检索/放置值的东西,因为键与该特定值映射。

但在内部,这种映射技术略有不同。
这个 HashMap 被定义为一个数组(假设为简单起见,我们的大小为 8)。

对键进行散列以识别该特定键值对将要存储的数组的位置。
一个。键可以是原始类型或对象
湾。根据key获取hashcode(如果是对象,我们应该在他们的类中实现更好的hashcode和equal方法)
C。此哈希码使索引和搜索更快。
d。数学 - 12112,科学 - 23454,泰米尔语 - 3222112,英语 - 3243212
我们不能将该键值对放入作为哈希码的索引中,因为它大于数组的长度。所以我们做 mod 来获取我们必须放置键值对的数组的位置。一个。数学将在 12112 % 8 = 0
湾。科学将在 23454 % 8 = 4
C。泰米尔语将在 3222112 % 8 = 0
d。英语将在 3243212 % 8 = 6
如果你仔细看,我们在第 0 个索引中有碰撞。我们如何解决这种碰撞?我们必须将两个键值对保存在同一个索引中为此,它们引入了 Node 或 Entry。节点具有该特定索引的键、值、哈希码和下一个节点。

当我们有冲突时,它将累加到下一个节点。所以最后会是这样。

hashMap 只不过是一个链表数组。所以每个位置都有一个数组的链表来避免冲突。
由于在链表中搜索的时间复杂度为 O(n),因此将这种 LinkedList 机制改为平衡 Tree。我们必须一一找到LinkedList中的确切元素。在平衡树中,它将是 O(log(n))。
在 Java 8 之后,hashmap 只不过是一个平衡树数组。