当我在浏览器 (FireFox) (View->Page Source) 中查看页面源代码时,将其复制并粘贴到我的 HTML 编辑器中,我查看的页面几乎相同(在本例中为 www.google.com)因为它出现在我的浏览器中。但是当我通过这段代码获得 HTML 源代码时(通过 Googles App Engines)
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print result.content
复制它并将其粘贴到我的 HTML 编辑器中,然后页面看起来完全不同。为什么会这样?代码有问题吗?
++++++++++++++++++++++++++++++++++
跟进:
到现在(准确地说,格林威治标准时间,2009 年 12 月 13 日,星期日,下午 1:01),我收到了两个评论问题(来自Aaron和Christian P. )和一个来自Alex Martelli的回答。
Aaron和Christian P.都在询问当 Fire-Fox 获得的源代码和 Google-App-Engine 获得的源代码都通过同一个 HTML 编辑器显示时,它们之间究竟有什么不同。
这里我也上传了屏幕截图:
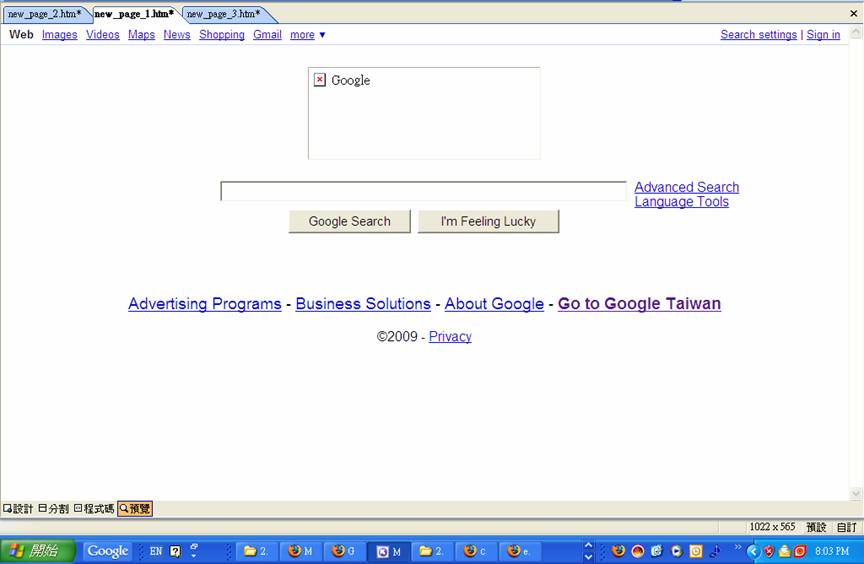{kind=link}
另一个显示 Google-App-Engine-obtained来源
{kind=link}
当它们都通过“MS Front Page”编辑器显示时。
一个非常明显的区别是不同的编码:在 Fire-Fox 代码中,所有内容都以英文显示,而在 Google-App-Engine 代码中,我得到了很多不同的符号。
另一个区别是 Google App Engine 代码中页面顶部的一些附加行。我认为,这就是Alex Martelli在他的回答中所说的(“……获取和打印方法也将包含元数据……”)。
另一个较小的区别是,谷歌图像的框在一个代码中被分成几个框,而在另一个代码中它保持完整。
Alex Martelli建议我使用这段代码(如果我理解正确的话):
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print "content-type: text/plain"
print
我已经尝试过了,但在这种情况下根本没有显示任何内容。
谢谢大家的回复,请继续回复——我真的很想看到这个问题最终得到解决。
++++++++++++++++++++++++++++++++++
跟进:
好的,问题已解决。
我没有完全注意Alex Martelli的说明,因此想出了一个错误的代码。这是他正确的一个:
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print "content-type: text/plain"
print
print result.content
此代码准确显示所需内容 - 页面顶部没有额外的行。
好吧,我仍然得到奇怪的符号,但我发现这可能是谷歌的问题。问题是我目前在台湾,谷歌似乎意识到了这一点并自动从 www.google.com (英文)切换到 www.google.com.tw (中文),但是这个,我猜,已经是另一个话题了。
感谢所有在这里回复的人。