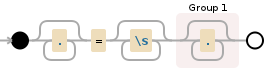
这是我试图在文本文件中识别的字符串。文本文件有一个我需要在每一行中提取的特定字段。前任:
Field1 = This is the content for field 1
Field2 = This is the content for field 2
Field3 = This is the content for field 3, which is = to 4445
假设我想在第一个“=”符号之后提取 field3 的内容。如何获得该内容“这是字段 3 的内容,即 = 到 4445”,包括第二个“=”符号但不包括第一个。我只是进入正则表达式,所以我没有太多经验。这是我尝试过的:
=.*
但这将打印第一个“=”符号及其之后的所有内容。我想省略第一个 = 符号。
同样,在没有第一个“=”符号的情况下获得“Field3”的正则表达式是什么?我知道我可以根据第一个等号分割线,但我真的需要用正则表达式来做。谢谢