我有一个包含两个字符值的列表,每个值在 Notepad++ 中各占一行。我正在尝试消除重复项,但我所写的只是匹配相隔一行的字符。
因此,如果我的列表如下所示:
ME, <- not matched
OR, |
ME, <- not matched
RI,
IL,
SD,
NV,
VA,
VA,
NY,
MN,
IL,
CA,
MI,
MO, <- match
MO, <- match
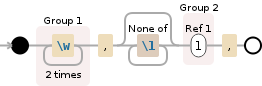
现在我正在使用这个。我该如何修改它,以便它发现重复的结果也超过一行
((\w{2}).*(\r\n)(\2))+
编辑
((\w{2}).*(\r\n))(.*\r\n)+\1这似乎工作得更好一些。