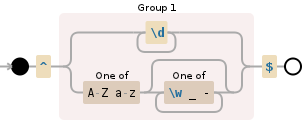
我试图找到所有看起来像abc_rtyorabc_45或abc09_23korabc09-K34的标记4535。标记不应以_或-或数字开头。
我没有取得任何进展,甚至失去了我所做的进展。这就是我现在所拥有的:
r'(?<!0-9)[(a-zA-Z)+]_(?=a-zA-Z0-9)|(?<!0-9)[(a-zA-Z)+]-(?=a-zA-Z0-9)\w+'
为了让问题更清楚,这里有一个例子:如果我有一个字符串如下:
D923-44 43 uou 08*) %%5 89ANB -iopu9 _M89 _97N hi_hello
然后它将接受
D923-44 and 43 and uou and hi_hello
它应该忽略
08*) %%5 89ANB -iopu9 _M89 _97N
我可能错过了一些案例,但我认为文字就足够了。抱歉,如果不是