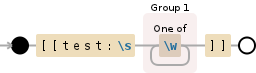
我的字符串看起来像这样,
lopsakf pkpsdkf pskadp fkpsdkfp sdaf
oksflksflslkf sdlf kasldfk lasdkf lsadfk
lopsakf pkpsdkf pskadp fkpsdkfp sdaf
oksflksflslkf sdlf kasldfk lasdkf lsadfk lopsakf pkpsdkf pskadp fkpsdkfp sdaf
oksflksflslkf sdlf kasldfk lasdkf lsadfk
[[test: lls]]
[[test: askd]]
[[test: mmdm]]
[[test: owow]]
[[test: www]]
[[test: wowow]]
我想获取 lls、askd、mmdm 等值并将其存储在列表中。请注意,此类文本数量巨大。我需要一种有效的方法来解析每个集合并将其存储在列表中,而不使用任何外部库。