我认为这种matlab格式是一种非常方便的存储和检索 numpy 数组的方法。速度非常快,而且磁盘和内存占用量完全一样。
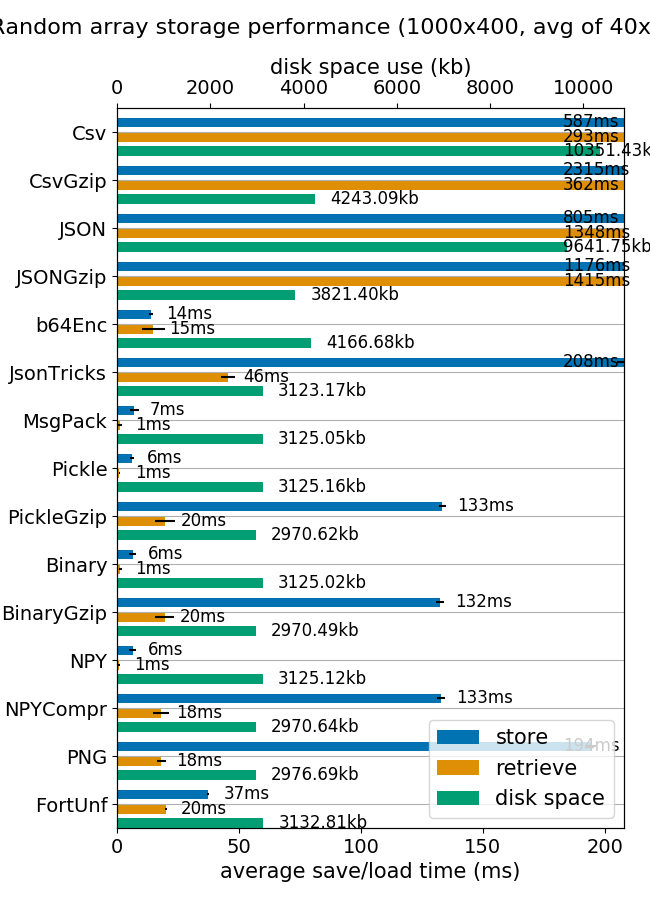
(来自mverleg 基准的图像)
但是如果出于任何原因需要将 numpy 数组存储到 SQLite 中,我建议添加一些压缩功能。
unutbu代码中的额外行非常简单
compressor = 'zlib' # zlib, bz2
def adapt_array(arr):
"""
http://stackoverflow.com/a/31312102/190597 (SoulNibbler)
"""
# zlib uses similar disk size that Matlab v5 .mat files
# bz2 compress 4 times zlib, but storing process is 20 times slower.
out = io.BytesIO()
np.save(out, arr)
out.seek(0)
return sqlite3.Binary(out.read().encode(compressor)) # zlib, bz2
def convert_array(text):
out = io.BytesIO(text)
out.seek(0)
out = io.BytesIO(out.read().decode(compressor))
return np.load(out)
使用 MNIST 数据库测试的结果是:
$ ./test_MNIST.py
[69900]: 99% remain: 0 secs
Storing 70000 images in 379.9 secs
Retrieve 6990 images in 9.5 secs
$ ls -lh example.db
-rw-r--r-- 1 agp agp 69M sep 22 07:27 example.db
$ ls -lh mnist-original.mat
-rw-r--r-- 1 agp agp 53M sep 20 17:59 mnist-original.mat
```
使用zlib, 和
$ ./test_MNIST.py
[69900]: 99% remain: 12 secs
Storing 70000 images in 8536.2 secs
Retrieve 6990 images in 37.4 secs
$ ls -lh example.db
-rw-r--r-- 1 agp agp 19M sep 22 03:33 example.db
$ ls -lh mnist-original.mat
-rw-r--r-- 1 agp agp 53M sep 20 17:59 mnist-original.mat
使用bz2
与SQLite 上的Matlab V5格式相比bz2,bz2 压缩率约为 2.8,但与 Matlab 格式相比,访问时间相当长(几乎是瞬间 vs 超过 30 秒)。Maybe 仅适用于真正庞大的数据库,其中学习过程比访问时间更耗时,或者需要尽可能小的数据库占用空间。
最后请注意,bipz/zlib比率约为 3.7,zlib/matlab需要多 30% 的空间。
如果您想自己玩,完整的代码是:
import sqlite3
import numpy as np
import io
compressor = 'zlib' # zlib, bz2
def adapt_array(arr):
"""
http://stackoverflow.com/a/31312102/190597 (SoulNibbler)
"""
# zlib uses similar disk size that Matlab v5 .mat files
# bz2 compress 4 times zlib, but storing process is 20 times slower.
out = io.BytesIO()
np.save(out, arr)
out.seek(0)
return sqlite3.Binary(out.read().encode(compressor)) # zlib, bz2
def convert_array(text):
out = io.BytesIO(text)
out.seek(0)
out = io.BytesIO(out.read().decode(compressor))
return np.load(out)
sqlite3.register_adapter(np.ndarray, adapt_array)
sqlite3.register_converter("array", convert_array)
dbname = 'example.db'
def test_save_sqlite_arrays():
"Load MNIST database (70000 samples) and store in a compressed SQLite db"
os.path.exists(dbname) and os.unlink(dbname)
con = sqlite3.connect(dbname, detect_types=sqlite3.PARSE_DECLTYPES)
cur = con.cursor()
cur.execute("create table test (idx integer primary key, X array, y integer );")
mnist = fetch_mldata('MNIST original')
X, y = mnist.data, mnist.target
m = X.shape[0]
t0 = time.time()
for i, x in enumerate(X):
cur.execute("insert into test (idx, X, y) values (?,?,?)",
(i, y, int(y[i])))
if not i % 100 and i > 0:
elapsed = time.time() - t0
remain = float(m - i) / i * elapsed
print "\r[%5d]: %3d%% remain: %d secs" % (i, 100 * i / m, remain),
sys.stdout.flush()
con.commit()
con.close()
elapsed = time.time() - t0
print
print "Storing %d images in %0.1f secs" % (m, elapsed)
def test_load_sqlite_arrays():
"Query MNIST SQLite database and load some samples"
con = sqlite3.connect(dbname, detect_types=sqlite3.PARSE_DECLTYPES)
cur = con.cursor()
# select all images labeled as '2'
t0 = time.time()
cur.execute('select idx, X, y from test where y = 2')
data = cur.fetchall()
elapsed = time.time() - t0
print "Retrieve %d images in %0.1f secs" % (len(data), elapsed)
if __name__ == '__main__':
test_save_sqlite_arrays()
test_load_sqlite_arrays()