我有一个看起来像下面的字符串
id=16&xxx&sid=3
xxx&sid=3&id=5
xxx&xxx&id=6
sid=5&xxxx
基本上,有id并且sid我想用正则表达式解析它们的值,但问题都以“id”结尾
我有以下正则表达式
ssid=(\d{1,})
id=(\d{1,})
我可以 id=(\d{1,})对它认为 ss(id)=xa 匹配的第二个表达式做些什么。考虑到我不知道表达式之前是什么,我能做些什么来解决这个问题?
只要前面没有ss
我有一个看起来像下面的字符串
id=16&xxx&sid=3
xxx&sid=3&id=5
xxx&xxx&id=6
sid=5&xxxx
基本上,有id并且sid我想用正则表达式解析它们的值,但问题都以“id”结尾
我有以下正则表达式
ssid=(\d{1,})
id=(\d{1,})
我可以 id=(\d{1,})对它认为 ss(id)=xa 匹配的第二个表达式做些什么。考虑到我不知道表达式之前是什么,我能做些什么来解决这个问题?
只要前面没有ss
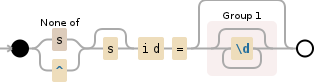
/(?:^|[^s])id=(\d+)/将匹配,除非前面有一个 s
正则表达式的第一部分:(?:^|[^s])意思是“匹配字符串的开头或除 s 之外的任何内容”
你还会注意到我切换到了\d{1,},\d+因为他们做同样的事情
更新:
由于您要避免的不是“sid”,而是“ssid”,请改用它:
/(?:^|[^s])s?id=(\d+)/
这将匹配 sid,但不匹配 ssid,如果这是您需要的
由于这看起来像 URL 的查询参数列表,我假设它是一个。
我不认为单个正则表达式是最好的匹配解决方案。最干净和明显的解决方案是:
&=,创建一个地图这样,您以后可以轻松地使用该字符串中的更多参数。它还有助于稍后阅读代码并直观地验证其正确性。
这通常扩展到 URL 处理。更好地将其解析为可读结构(无论您的语言是什么),并为各个部分使用访问函数。由于 URL 部分的正确转义和反转义并非易事,因此应该有一个小库。