您的表达式匹配第一个点,.*?也将匹配点。因此,您将获得Shyam and you...匹配。尝试更改(.*?are.*?)为([^\\.]*?are[^\\.]*?)以匹配除点以外的所有字符。
请注意,您还可以将表达式简化为\s*([^\.]*are[^\.]*)(此处为非 Java 表示法)。这将具有相同的结果,但也会匹配"You are Shyam. You are Mike."。
此表达式将匹配任何不是点的字符序列,中间有一个“are”,前面是可选的空格。请注意,这也将are单独匹配,因此您可能需要更改[^\.]*为[^\.]+.
编辑:
为了说明您更新的示例,您可以尝试以下表达式(以下是细分):
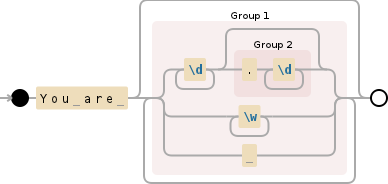
\s*((?:[^\.]|(?:\w+\.)+\w)*are.*?)(?:\.\s|\.$)
输入:I am here. You are almost 2.3 km away from home. You are Mike. You are 2. 2.3 percent of them are 2.3 percent of all. Sections 2.3.a to 2.3.c are 3 sections. This is garbage.
输出:You are almost 2.3 km away from home, You are Mike, You are 2, 2.3 percent of them are 2.3 percent of all,Sections 2.3.a to 2.3.c are 3 sections
一些注意事项:这将要求每个句子都以一个点结尾(这可以通过替换为来更改\.\s|\.$)[.!?]\s|[.!?]$,每个分隔点后跟一个空格或输入的结尾,并且不会匹配You are J. J. Abrams或2.a
请注意,在这种情况下,计算机很难确定句子的结尾,尤其是使用“简单”正则表达式。
表达式分解:
\s*前导空格不会是组的一部分,否则不需要((?:[^\.]|(?:\w+\.)+\w)*are.*?)捕获的组,包含are前后的文本和附加文本
(?:[^\.]|(?:\w+\.)+\w)一个非捕获组匹配任何非点字符序列( )或[^\.]( )|\w[a-zA-Z0-9_](?:\w+\.)+\w).*?任何字符序列,但使用惰性修饰符来匹配最短的可能序列而不是最长的序列(没有它,下一部分将没有多大意义)
(?:\.\s|\.$)必须跟随捕获组的非捕获组,它必须匹配一个点后跟空格 ( \.\s) 或 ( |) 输入末尾的一个点 ( \.$)
编辑 2:
这是一个没有(A|B)*组的未经彻底测试的版本:
\s*([^.]*(?:(?:\w+\.)+\w+[^.]*)*are.*?)(?:[.!?]\s|[.!?]$)
基本上(?:[^\.]|(?:\w+\.)+\w)*已被替换为[^.]*(?:(?:\w+\.)+\w+[^.]*)*,这意味着“任何非点字符序列后跟任意数量的序列,这些序列由单词字符包围的点组成,然后是任何非点字符序列”。;)