你可以试试下一个:
private static final Pattern REGEX_PATTERN =
Pattern.compile("\\B\"\\w*( \\w*)*\"\\B");
private static String replaceNotPairs(String input) {
StringBuffer sb = new StringBuffer();
Matcher matcher = REGEX_PATTERN.matcher(input);
int start = 0;
int last = 0;
while (matcher.find()) {
start = matcher.start();
sb.append(input.substring(last, start).replace("\"", "\\\""));
last = matcher.end();
sb.append(matcher.group());
}
sb.append(input.substring(last).replace("\"", "\\\""));
return sb.toString();
}
例如:
public static void main(String[] args) {
System.out.printf("src: %s%nout: %s%n%n",
"\"ABC def\" xxy\"u",
replaceNotPairs("\"ABC def\" xxy\"u"));
System.out.printf("src: %s%nout: %s%n%n",
"\"111\" \"222\" \"333\" \"4",
replaceNotPairs("\"111\" \"222\" \"333\" \"4"));
System.out.printf("src: %s%nout: %s%n%n",
"\"AAA\" \"bbb\" \"CCC \"DDD\"",
replaceNotPairs("\"AAA\" \"bbb\" \"CCC \"DDD\""));
System.out.printf("src: %s%nout: %s%n%n",
"\"4 \"111\" \"222\"",
replaceNotPairs("\"4 \"111\" \"222\""));
System.out.printf("src: %s%nout: %s%n%n",
"\"11\" \"2 \"333\"",
replaceNotPairs("\"11\" \"2 \"333\""));
}
示例输入的输出:
src: "ABC def" xxy"u
out: "ABC def" xxy\"u
src: "111" "222" "333" "4
out: "111" "222" "333" \"4
src: "AAA" "bbb" "CCC "DDD"
out: "AAA" "bbb" \"CCC "DDD"
src: "4 "111" "222"
out: \"4 "111" "222"
src: "11" "2 "333"
out: "11" \"2 "333"
请参阅正则表达式的解释:
\B\"\w*( \w*)*\"\B
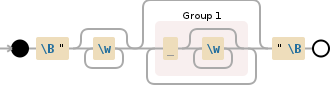
(来自 http://rick.measham.id.au/paste/explain.pl?regex):
NODE EXPLANATION
----------------------------------------------------------------------------
\B the boundary between two word chars (\w)
or two non-word chars (\W)
----------------------------------------------------------------------------
\" '"'
----------------------------------------------------------------------------
\w* word characters (a-z, A-Z, 0-9, _) (0 or
more times (matching the most amount
possible))
----------------------------------------------------------------------------
( group and capture to \1 (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------------
' '
----------------------------------------------------------------------------
\w* word characters (a-z, A-Z, 0-9, _) (0 or
more times (matching the most amount
possible))
----------------------------------------------------------------------------
)* end of \1 (NOTE: because you are using a
quantifier on this capture, only the LAST
repetition of the captured pattern will be
stored in \1)
----------------------------------------------------------------------------
\" '"'
----------------------------------------------------------------------------
\B the boundary between two word chars (\w)
or two non-word chars (\W)