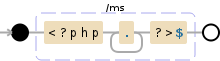
你可以试试这个模式:
$pattern = <<<'LOD'
~
#definitions
(?(DEFINE)
(?<sq> '(?:[^'\\]+|\\.)*+' ) # content inside simple quotes
(?<dq> "(?:[^"\\]+|\\.)*+" ) # content inside double quotes
(?<vn> [a-zA-Z_]\w*+ ) # variable name
(?<hndoc> <<< (["']?) (\g<vn>) \g{-2} \R # content inside here/nowdoc
(?: [^\r\n]+ | \R+ (?!\g{-1}; $) )*+
\R \g{-1}; \R
)
(?<cmt> /\* # multiline comments
(?> [^*]+ | \* (?!/) )*+
\*/
)
)
#pattern
<\?php \s+
(?: [^"'?/<]+ | \?+(?!>) | \g<sq> | \g<dq> | \g<hndoc> | \g<cmt> | [</]+ )*+
(?: \?> | \z )
~xsm
LOD;
测试:
$subject = <<<'LOD'
<h1>Extract the PHP Code</h1>
<?php
echo(date("F j, Y, g:i a") . ' and a stumbling block: ?>');
/* Another stumbling block ?> */
echo <<<'EOD'
Youpi!!! ?>
EOD;
echo(' that works.');
?>
<p>Some HTML text ...</p>
LOD;
preg_match_all($pattern, $subject, $matches);
print_r($matches);
另一种方式:
正如马里奥在评论中建议的那样,您可以使用分词器。这是最简单的方法,因为您不必定义任何内容,例如:
$tokens = token_get_all($subject);
$display = false;
foreach ($tokens as $token) {
if (is_array($token)) {
if ($token[0]==T_OPEN_TAG) $display = true;
if ($display) echo $token[1];
if ($token[0]==T_CLOSE_TAG) $display = false;
} else {
if ($display) echo $token;
}
}