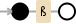
首先,如果你想匹配 AZ 范围内的某个字符,你需要把它放在方括号中。这个
.replaceAll("A-Z|ss$", "SS")
将在源代码中查找三个字符 AZ,这不是您想要的。其次,我认为你对什么感到困惑 | 方法。如果你这样说:
.replaceAll("[A-Z]|ss$", "SS")
它将用 SS 替换单词末尾的任何大写字母,因为 | 意思是寻找这个或那个。
您的方法的第三个问题是,第二个和第三个 replaceAll 将查找原始字符串中的任何 ss,即使它不是来自 ß。这可能是也可能不是您想要的。
这是我要做的:
String replaceUml = str
.replaceAll("(?<=[A-Z])ß", "SS")
.replaceAll("ß", "ss");
如果 ß 之前的字符是大写字母,这将首先用 SS 替换所有 ß;然后如果有剩余的 ß,它们将被 ss 替换。实际上,如果 ß 之前的字符是 Ä 之类的变音符号,这将不起作用,因此您可能应该将其更改为
String replaceUml = str
.replaceAll("(?<=[A-ZÄÖÜ])ß", "SS")
.replaceAll("ß", "ss");
(可能有更好的方法来指定“大写 Unicode 字母”;我会寻找它。)
编辑:
String replaceUml = str
.replaceAll("(?<=\\p{Lu})ß", "SS")
.replaceAll("ß", "ss");
一个问题是,如果 ß 是文本中的第二个字符,并且单词的第一个字母是大写的,但单词的其余部分不是,则它不起作用。在这种情况下,您可能需要小写的“ss”。
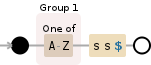
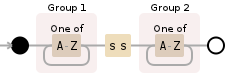
String replaceUml = str
.replaceAll("(?<=\\b\\p{Lu})ß(?=\\P{Lu})", "ss")
.replaceAll("(?<=\\p{Lu})ß", "SS")
.replaceAll("ß", "ss");
现在第一个将 ß 替换为 ss 如果它前面有一个大写字母,该字母是单词的第一个字母,但后面有一个不是大写字母的字符。 \P{Lu}带有大写字母 P 将匹配除大写字母以外的任何字符(它是\p{Lu}带有小写字母 p 的负数)。我还包括 \b 来测试单词的第一个字符。