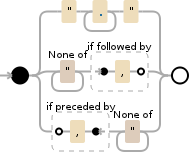
描述
而不是使用拆分,我认为简单地执行匹配并处理所有找到的匹配会更容易。
该表达式将:
- 用逗号分隔您的示例文本
- 将处理空值
- 将忽略双引号逗号,前提是双引号没有嵌套
- 从返回值中修剪分隔逗号
- 从返回的值中修剪周围的引号
正则表达式: (?:^|,)(?=[^"]|(")?)"?((?(1)[^"]*|[^,"]*))"?(?=,|$)

例子
示例文本
123,2.99,AMO024,Title,"Description, more info",,123987564
使用非 java 表达式的 ASP 示例
Set regEx = New RegExp
regEx.Global = True
regEx.IgnoreCase = True
regEx.MultiLine = True
sourcestring = "your source string"
regEx.Pattern = "(?:^|,)(?=[^""]|("")?)""?((?(1)[^""]*|[^,""]*))""?(?=,|$)"
Set Matches = regEx.Execute(sourcestring)
For z = 0 to Matches.Count-1
results = results & "Matches(" & z & ") = " & chr(34) & Server.HTMLEncode(Matches(z)) & chr(34) & chr(13)
For zz = 0 to Matches(z).SubMatches.Count-1
results = results & "Matches(" & z & ").SubMatches(" & zz & ") = " & chr(34) & Server.HTMLEncode(Matches(z).SubMatches(zz)) & chr(34) & chr(13)
next
results=Left(results,Len(results)-1) & chr(13)
next
Response.Write "<pre>" & results
使用非 java 表达式匹配
第 0 组获取包含逗号的整个子字符串
第 1 组在使用时获取引号
第 2 组获取不包括逗号的值
[0][0] = 123
[0][1] =
[0][2] = 123
[1][0] = ,2.99
[1][1] =
[1][2] = 2.99
[2][0] = ,AMO024
[2][1] =
[2][2] = AMO024
[3][0] = ,Title
[3][1] =
[3][2] = Title
[4][0] = ,"Description, more info"
[4][1] = "
[4][2] = Description, more info
[5][0] = ,
[5][1] =
[5][2] =
[6][0] = ,123987564
[6][1] =
[6][2] = 123987564