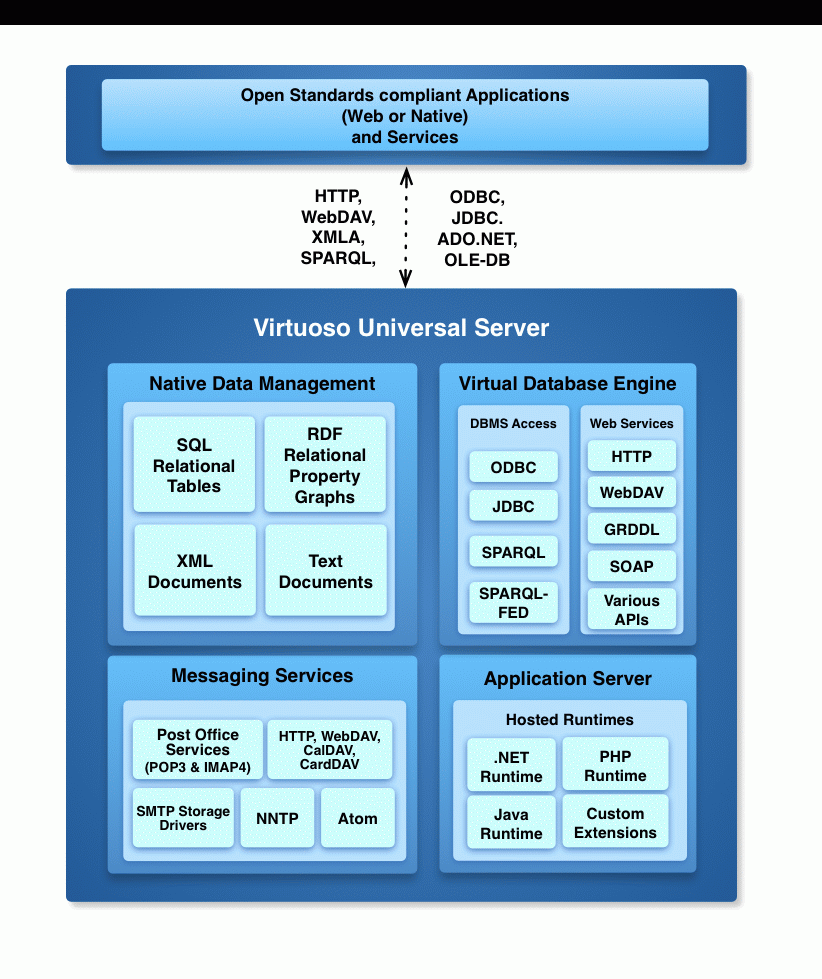
Virtuoso 实际上是一整套应用程序和服务层,构建在他们自己的 SQL 数据库之上,因此可以理解的混淆。
Native RDF Quad Store 是 Virtuoso 自己的 Quad Store 实现,讽刺的是,正如您所指出的,它实际上是基于 SQL 的。这完全在 Virtuoso 自己的 SQL 数据库实现中存储和实现。因此,尽管它是基于 SQL 的,但它具有固定的表布局并使用自定义数据类型来存储数据。
基于 SQL 的 RDF 三重存储是指 Virtuoso 商业版本的一项功能,它允许您定义映射规则以将任意普通关系数据库(基于 Virtuoso 和其他基于后端的数据库,例如 MySql、PostgreSQL)视为 RDF 存储。
性能差异
性能差异来自这样一个事实,即 Native Quad 存储具有已知的布局、自定义 RDF 数据类型以及 Virtuoso 堆栈中特定于它的许多软件优化。因此,当 Virtuoso 接收 SPARQL 并将其编译为等效的 SQL 查询时,它在他们的数据库上运行非常高效。使用自定义 RDF 数据类型允许他们将所有 SPARQL 逻辑下推到查询引擎层,这也使评估更快。
对于基于 SQL 的三重存储,涉及到一个映射层,它们必须调用 SQL 数据库(可能是外部的)并将其内容转换为 RDF 形式,以便随后进行必要的计算来回答 SPARQL 查询。映射步骤的成本可能非常高,并且使查询更难优化,因为它们访问的关于 RDF 数据的前期信息较少。
另外,由于数据通常只是标准 SQL 类型,因此它们无法将某些逻辑下推到底层查询引擎,因为 SQL 和 SPARQL 类型语义在许多情况下不一致。因此,必须提取、适当转换这些值,然后在查询引擎层之上计算表达式结果,然后根据需要反馈回来。这会降低性能,因为引擎必须在不同的处理上下文之间切换,并且可能会进行许多 SQL 查询来回答相同的 SPARQL 查询。
{kind=link}