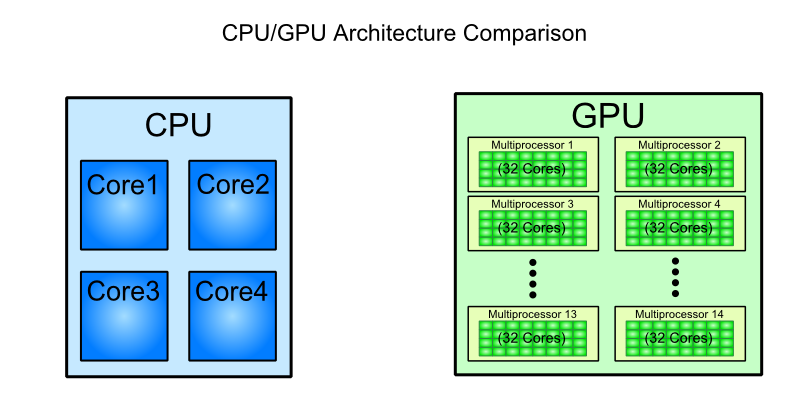
我要向那些(几乎)不知道 GPU 工作原理的人做一个演示。我认为说 GPU 有 1000 个内核而 CPU 只有 4 到 8 个内核是无稽之谈。但我想给我的听众一个比较的元素。
在使用 NVidia 的 Kepler 和 AMD 的 GCN 架构几个月后,我很想将GPU“核心”与CPU 的 SIMD ALU进行比较(我不知道他们在英特尔是否有这样的名字)。公平吗?毕竟,在查看汇编级别时,这些编程模型有很多共同点(至少对于 GCN,请查看ISA 手册的p2-6)。
这篇文章指出,Haswell 处理器每个周期可以执行 32 次单精度操作,但我想有流水线或其他事情发生以实现该速率。用 NVidia 的话来说,这个处理器有多少个 Cuda 内核?对于 32 位操作,我会说每个 CPU 内核 8 个,但这只是基于 SIMD 宽度的猜测。
当然,在比较 CPU 和 GPU 硬件时还有很多其他的事情需要考虑,但这不是我想要做的。我只需要解释这件事是如何工作的。
PS:非常感谢所有指向CPU硬件文档或 CPU/GPU 演示文稿的指针!
编辑: 感谢您的回答,遗憾的是我只能选择其中一个。我标记了Igor 的答案,因为它最符合我最初的问题,并给了我足够的信息来证明为什么这种比较不应该走得太远,但是CaptainObvious 提供了非常好的文章。
{kind=link}