我正在寻找将正则表达式转换为 NFA。我知道我们需要将正则表达式转换为解析树,然后将其转换为 NFA。我正在使用java脚本。是否有任何 js 工具可以直接从给定的正则表达式生成解析树?
我也对解析树到 NFA 部分的转换感到困惑。
我正在寻找将正则表达式转换为 NFA。我知道我们需要将正则表达式转换为解析树,然后将其转换为 NFA。我正在使用java脚本。是否有任何 js 工具可以直接从给定的正则表达式生成解析树?
我也对解析树到 NFA 部分的转换感到困惑。
为什么要构建一个解析树呢?将正则表达式直接转换为 NFA 相对简单。
有有限数量的基本情况。知道了这些,我们就可以从这些案例的某种组合中构建完整的 NFA。 考虑构造一些正则表达式 R 的所有可能方式。
前三个很容易,但联合、连接和 Kleene 闭包需要一点思考。
我在这里找到了最后 3 个很好的图片:http: //www.codeproject.com/KB/recipes/OwnRegExpressionsParser/Thompson.jpg
将微不足道地成为不接受状态的途径。(令 O 为不接受状态,X 为接受。)
(->O)
接受状态的路径。
(->X)
带有字符串“a”路径的开始状态到接受状态。
(->Oa>X)
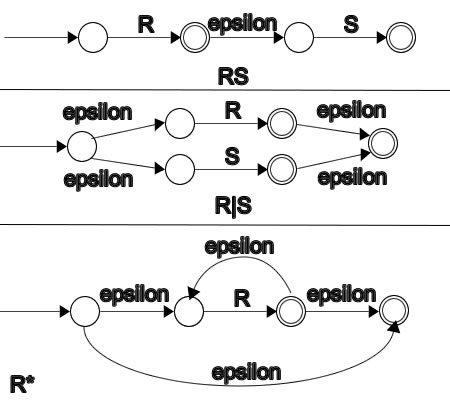
开始状态变为 R1 的开始状态,在 R1 的接受状态和 R2 的开始状态之间添加了 epsilon 转换,从 R1 的接受状态被移除。在图中,第二个状态是接受,但它不应该是。
R1 和 R2 的具有到 NFA 的 epsilon 转换的开始状态——如果可能,机器将“猜测”进入哪个以被接受。图中,R1 和 R2 分别用 R 和 S 表示。
添加一个 epsilon 转换,以便 R1 可以永远循环!
现在我们已经有了所有初始可能性的公式,它们可以组合成一个大型 NFA。例如,对于 (AUB) ∘ C*
可以证明任何 NFA 都可以这样归纳构造,并且我提供的所有初始构造都是正确的。嗯。
遗憾的是,我不熟悉任何可以满足您要求的 js 工具,但是根据上面的信息,如果您使用一些合理的表示来存储基本案例,那么代码应该相当简单。
要获得更彻底且睡眠不足的解释,请尝试http://www.codeproject.com/Articles/5412/Writing-own-regular-expression-parser 你会想真正理解汤普森的算法(我已经描述),然后再深入研究编码。该网站看起来比我在这里更深入地了解实施。
祝你好运!
{kind=link}