我有一个以出现一次或多次的序列开头的字符串"Re:"。这"Re:"可以是任何组合,例如。Re<any number of spaces>:, re:, re<any number of spaces>:, RE:,RE<any number of spaces>:等
字符串的示例序列:Re: Re : Re : re : RE: This is a Re: sample string.
我想定义一个 java 正则表达式,它将识别并去除所有出现的Re:,但只有字符串开头的那些,而不是字符串中出现的那些。
所以输出应该看起来像This is a Re: sample string.
这是我尝试过的:
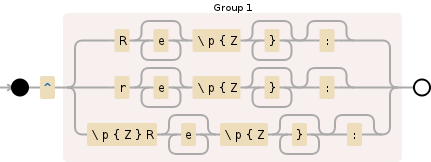
String REGEX = "^(Re*\\p{Z}*:?|re*\\p{Z}*:?|\\p{Z}Re*\\p{Z}*:?)";
String INPUT = title;
String REPLACE = "";
Pattern p = Pattern.compile(REGEX);
Matcher m = p.matcher(INPUT);
while(m.find()){
m.appendReplacement(sb,REPLACE);
}
m.appendTail(sb);
我p{Z}用来匹配空格(在这个论坛的某个地方找到了这个,因为 Java 正则表达式没有识别\s)。
我在这段代码中面临的问题是搜索在第一个匹配时停止,并转义了 while 循环。