并非所有蓄能器都在$project阶段可用。我们需要考虑在项目中我们可以在累加器方面做什么以及我们可以在小组中做什么。让我们来看看这个:
db.companies.aggregate([{
$match: {
funding_rounds: {
$ne: []
}
}
}, {
$unwind: "$funding_rounds"
}, {
$sort: {
"funding_rounds.funded_year": 1,
"funding_rounds.funded_month": 1,
"funding_rounds.funded_day": 1
}
}, {
$group: {
_id: {
company: "$name"
},
funding: {
$push: {
amount: "$funding_rounds.raised_amount",
year: "$funding_rounds.funded_year"
}
}
}
}, ]).pretty()

我们在哪里检查是否有任何funding_rounds不为空。然后它被unwind编辑到$sort后面的阶段。我们将为funding_rounds每个公司的数组的每个元素看到一个文档。所以,我们在这里要做的第一件事是$sort基于:
funding_rounds.funded_yearfunding_rounds.funded_monthfunding_rounds.funded_day
在按公司名称分组的小组赛中,阵列正在使用$push. $push应该是文档的一部分,指定为我们在小组赛中命名的字段的值。我们可以推送任何有效的表达式。在这种情况下,我们将文档推送到此数组,并且对于我们推送的每个文档,它都被添加到我们正在累积的数组的末尾。在这种情况下,我们正在推动由raised_amountand构建的文档funded_year。因此,该$group阶段是一个文档流,_id其中包含我们指定公司名称的位置。
请注意,它$push是$group分阶段可用的,但不是$project分阶段的。这是因为$group阶段旨在获取一系列文档并根据该文档流累积值。
$project另一方面,一次处理一个文档。因此,我们可以计算项目阶段内单个文档中数组的平均值。但是做这样的事情,一次一个,我们看到文件,对于每一个文件,它通过小组赛阶段推动一个新的价值,这$project不是舞台设计要做的事情。对于我们想要使用的那种操作$group。
让我们看另一个例子:
db.companies.aggregate([{
$match: {
funding_rounds: {
$exists: true,
$ne: []
}
}
}, {
$unwind: "$funding_rounds"
}, {
$sort: {
"funding_rounds.funded_year": 1,
"funding_rounds.funded_month": 1,
"funding_rounds.funded_day": 1
}
}, {
$group: {
_id: {
company: "$name"
},
first_round: {
$first: "$funding_rounds"
},
last_round: {
$last: "$funding_rounds"
},
num_rounds: {
$sum: 1
},
total_raised: {
$sum: "$funding_rounds.raised_amount"
}
}
}, {
$project: {
_id: 0,
company: "$_id.company",
first_round: {
amount: "$first_round.raised_amount",
article: "$first_round.source_url",
year: "$first_round.funded_year"
},
last_round: {
amount: "$last_round.raised_amount",
article: "$last_round.source_url",
year: "$last_round.funded_year"
},
num_rounds: 1,
total_raised: 1,
}
}, {
$sort: {
total_raised: -1
}
}]).pretty()
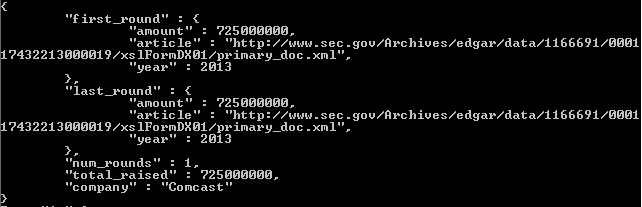
在$group舞台上,我们使用$first和$last累加器。对,我们可以再次看到$push- 我们不能在项目阶段使用$first和$last。因为同样,项目阶段并非旨在根据多个文档累积价值。相反,它们旨在一次重塑一个文档。使用算子计算总轮数$sum。值1仅计算通过该组的文档数以及匹配或分组在给定_id值下的每个文档的数量。该项目可能看起来很复杂,但它只是使输出变得漂亮。只是它包含num_rounds和total_raised来自上一个文档。