我在重写规则以将解析树转换为 antlr 中的 AST 树时遇到问题。
这是我的antlr代码:
grammar MyGrammar;
options {
output= AST;
ASTLabelType=CommonTree;
backtrack = true;
}
tokens {
NP;
NOUN;
ADJ;
}
//NOUN PHRASE
np : ( (adj)* n+ (adj)* -> ^(ADJ adj)* ^(NOUN n)+ ^(ADJ adj)* )
;
adj : 'adj1'|'adj2';
n : 'noun1';
当我输入 "adj1 noun1 adj2" 时,解析树的结果如下:
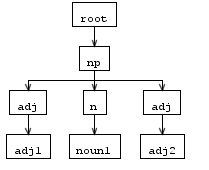
但是重写规则后的AST 树似乎与解析树不完全一样,adj 是双精度的,并且不是按顺序排列的,像这样:
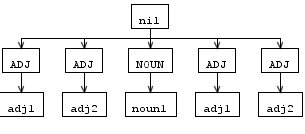
所以我的问题是如何重写规则以获得像上面的解析树一样的结果?