我想了解有关使用SSE的更多信息。
除了显而易见的阅读英特尔® 64 和 IA-32 架构软件开发人员手册之外,还有哪些学习方法?
主要是我有兴趣使用GCC X86 Built-in Functions。
我想了解有关使用SSE的更多信息。
除了显而易见的阅读英特尔® 64 和 IA-32 架构软件开发人员手册之外,还有哪些学习方法?
主要是我有兴趣使用GCC X86 Built-in Functions。
首先,我不建议使用内置函数——它们不可移植(跨同一架构的编译器)。
使用内在函数,GCC在将SSE 内在函数优化为更优化的代码方面做得非常出色。您可以随时查看程序集,了解如何充分利用 SSE。
内在函数很简单——就像正常的函数调用一样:
#include <immintrin.h> // portable to all x86 compilers
int main()
{
__m128 vector1 = _mm_set_ps(4.0, 3.0, 2.0, 1.0); // high element first, opposite of C array order. Use _mm_setr_ps if you want "little endian" element order in the source.
__m128 vector2 = _mm_set_ps(7.0, 8.0, 9.0, 0.0);
__m128 sum = _mm_add_ps(vector1, vector2); // result = vector1 + vector 2
vector1 = _mm_shuffle_ps(vector1, vector1, _MM_SHUFFLE(0,1,2,3));
// vector1 is now (1, 2, 3, 4) (above shuffle reversed it)
return 0;
}
使用_mm_load_ps或_mm_loadu_ps从数组加载数据。
当然还有更多的选择,SSE 真的很强大,在我看来相对容易学习。
有关指南的一些链接,另请参阅https://stackoverflow.com/tags/sse/info。
由于您要求资源:
使用 C++ 使用 SSE 的实用指南:关于如何有效使用 SSE 的良好概念概述,并附有示例。
MSDN List of Compiler Intrinsics:满足您所有内在需求的综合参考。它是 MSDN,但这里列出的几乎所有内在函数都受 GCC 和 ICC 支持。
Christopher Wright 的 SSE 页面:关于 SSE 操作码含义的快速参考。我猜英特尔手册可以提供相同的功能,但这更快。
最好用内在函数编写大部分代码,但请检查编译器输出的 objdump 以确保它生成高效的代码。SIMD 代码生成仍然是一项相当新的技术,在某些情况下编译器很可能会出错。
我发现 Agner Fog 博士的研究和优化指南非常有价值!他还有一些我还没有尝试过的库和测试工具。 http://www.agner.org/optimize/
第 1 步:手动编写一些程序集
我建议您首先尝试手动编写自己的程序集,以便在您开始学习时准确查看和控制正在发生的事情。
那么问题就变成了如何观察程序中发生了什么,答案是:
printand assertthings自己使用 C 标准库需要做一些工作,但没什么。例如,在我的测试设置的以下文件中,我在 Linux 上为您很好地完成了这项工作:
使用这些助手,然后我开始使用基础知识,例如:
addpd.S
#include <lkmc.h>
LKMC_PROLOGUE
.data
.align 16
addps_input0: .float 1.5, 2.5, 3.5, 4.5
addps_input1: .float 5.5, 6.5, 7.5, 8.5
addps_expect: .float 7.0, 9.0, 11.0, 13.0
addpd_input0: .double 1.5, 2.5
addpd_input1: .double 5.5, 6.5
addpd_expect: .double 7.0, 9.0
.bss
.align 16
output: .skip 16
.text
/* 4x 32-bit */
movaps addps_input0, %xmm0
movaps addps_input1, %xmm1
addps %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, addps_expect, $0x10)
/* 2x 64-bit */
movaps addpd_input0, %xmm0
movaps addpd_input1, %xmm1
addpd %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, addpd_expect, $0x10)
LKMC_EPILOGUE
paddq.S
#include <lkmc.h>
LKMC_PROLOGUE
.data
.align 16
input0: .long 0xF1F1F1F1, 0xF2F2F2F2, 0xF3F3F3F3, 0xF4F4F4F4
input1: .long 0x12121212, 0x13131313, 0x14141414, 0x15151515
paddb_expect: .long 0x03030303, 0x05050505, 0x07070707, 0x09090909
paddw_expect: .long 0x04030403, 0x06050605, 0x08070807, 0x0A090A09
paddd_expect: .long 0x04040403, 0x06060605, 0x08080807, 0x0A0A0A09
paddq_expect: .long 0x04040403, 0x06060606, 0x08080807, 0x0A0A0A0A
.bss
.align 16
output: .skip 16
.text
movaps input1, %xmm1
/* 16x 8bit */
movaps input0, %xmm0
paddb %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddb_expect, $0x10)
/* 8x 16-bit */
movaps input0, %xmm0
paddw %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddw_expect, $0x10)
/* 4x 32-bit */
movaps input0, %xmm0
paddd %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddd_expect, $0x10)
/* 2x 64-bit */
movaps input0, %xmm0
paddq %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddq_expect, $0x10)
LKMC_EPILOGUE
第 2 步:编写一些内在函数
但是,对于生产代码,您可能希望使用预先存在的内在函数而不是原始程序集,如下所述:https ://stackoverflow.com/a/1390802/895245
所以现在我尝试将前面的示例转换为或多或少等效的具有内在函数的 C 代码。
添加pq.c
#include <assert.h>
#include <string.h>
#include <x86intrin.h>
float global_input0[] __attribute__((aligned(16))) = {1.5f, 2.5f, 3.5f, 4.5f};
float global_input1[] __attribute__((aligned(16))) = {5.5f, 6.5f, 7.5f, 8.5f};
float global_output[4] __attribute__((aligned(16)));
float global_expected[] __attribute__((aligned(16))) = {7.0f, 9.0f, 11.0f, 13.0f};
int main(void) {
/* 32-bit add (addps). */
{
__m128 input0 = _mm_set_ps(1.5f, 2.5f, 3.5f, 4.5f);
__m128 input1 = _mm_set_ps(5.5f, 6.5f, 7.5f, 8.5f);
__m128 output = _mm_add_ps(input0, input1);
/* _mm_extract_ps returns int instead of float:
* * https://stackoverflow.com/questions/5526658/intel-sse-why-does-mm-extract-ps-return-int-instead-of-float
* * https://stackoverflow.com/questions/3130169/how-to-convert-a-hex-float-to-a-float-in-c-c-using-mm-extract-ps-sse-gcc-inst
* so we must use instead: _MM_EXTRACT_FLOAT
*/
float f;
_MM_EXTRACT_FLOAT(f, output, 3);
assert(f == 7.0f);
_MM_EXTRACT_FLOAT(f, output, 2);
assert(f == 9.0f);
_MM_EXTRACT_FLOAT(f, output, 1);
assert(f == 11.0f);
_MM_EXTRACT_FLOAT(f, output, 0);
assert(f == 13.0f);
/* And we also have _mm_cvtss_f32 + _mm_shuffle_ps, */
assert(_mm_cvtss_f32(output) == 13.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 1)) == 11.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 2)) == 9.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 3)) == 7.0f);
}
/* Now from memory. */
{
__m128 *input0 = (__m128 *)global_input0;
__m128 *input1 = (__m128 *)global_input1;
_mm_store_ps(global_output, _mm_add_ps(*input0, *input1));
assert(!memcmp(global_output, global_expected, sizeof(global_output)));
}
/* 64-bit add (addpd). */
{
__m128d input0 = _mm_set_pd(1.5, 2.5);
__m128d input1 = _mm_set_pd(5.5, 6.5);
__m128d output = _mm_add_pd(input0, input1);
/* OK, and this is how we get the doubles out:
* with _mm_cvtsd_f64 + _mm_unpackhi_pd
* https://stackoverflow.com/questions/19359372/mm-cvtsd-f64-analogon-for-higher-order-floating-point
*/
assert(_mm_cvtsd_f64(output) == 9.0);
assert(_mm_cvtsd_f64(_mm_unpackhi_pd(output, output)) == 7.0);
}
return 0;
}
paddq.c
#include <assert.h>
#include <inttypes.h>
#include <string.h>
#include <x86intrin.h>
uint32_t global_input0[] __attribute__((aligned(16))) = {1, 2, 3, 4};
uint32_t global_input1[] __attribute__((aligned(16))) = {5, 6, 7, 8};
uint32_t global_output[4] __attribute__((aligned(16)));
uint32_t global_expected[] __attribute__((aligned(16))) = {6, 8, 10, 12};
int main(void) {
/* 32-bit add hello world. */
{
__m128i input0 = _mm_set_epi32(1, 2, 3, 4);
__m128i input1 = _mm_set_epi32(5, 6, 7, 8);
__m128i output = _mm_add_epi32(input0, input1);
/* _mm_extract_epi32 mentioned at:
* https://stackoverflow.com/questions/12495467/how-to-store-the-contents-of-a-m128d-simd-vector-as-doubles-without-accessing/56404421#56404421 */
assert(_mm_extract_epi32(output, 3) == 6);
assert(_mm_extract_epi32(output, 2) == 8);
assert(_mm_extract_epi32(output, 1) == 10);
assert(_mm_extract_epi32(output, 0) == 12);
}
/* Now from memory. */
{
__m128i *input0 = (__m128i *)global_input0;
__m128i *input1 = (__m128i *)global_input1;
_mm_store_si128((__m128i *)global_output, _mm_add_epi32(*input0, *input1));
assert(!memcmp(global_output, global_expected, sizeof(global_output)));
}
/* Now a bunch of other sizes. */
{
__m128i input0 = _mm_set_epi32(0xF1F1F1F1, 0xF2F2F2F2, 0xF3F3F3F3, 0xF4F4F4F4);
__m128i input1 = _mm_set_epi32(0x12121212, 0x13131313, 0x14141414, 0x15151515);
__m128i output;
/* 8-bit integers (paddb) */
output = _mm_add_epi8(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x03030303);
assert(_mm_extract_epi32(output, 2) == 0x05050505);
assert(_mm_extract_epi32(output, 1) == 0x07070707);
assert(_mm_extract_epi32(output, 0) == 0x09090909);
/* 32-bit integers (paddw) */
output = _mm_add_epi16(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04030403);
assert(_mm_extract_epi32(output, 2) == 0x06050605);
assert(_mm_extract_epi32(output, 1) == 0x08070807);
assert(_mm_extract_epi32(output, 0) == 0x0A090A09);
/* 32-bit integers (paddd) */
output = _mm_add_epi32(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04040403);
assert(_mm_extract_epi32(output, 2) == 0x06060605);
assert(_mm_extract_epi32(output, 1) == 0x08080807);
assert(_mm_extract_epi32(output, 0) == 0x0A0A0A09);
/* 64-bit integers (paddq) */
output = _mm_add_epi64(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04040404);
assert(_mm_extract_epi32(output, 2) == 0x06060605);
assert(_mm_extract_epi32(output, 1) == 0x08080808);
assert(_mm_extract_epi32(output, 0) == 0x0A0A0A09);
}
return 0;
第 3 步:去优化一些代码并对其进行基准测试
最后一步,也是最重要和最困难的一步,当然是实际使用内在函数来使您的代码更快,然后对您的改进进行基准测试。
这样做可能需要您了解一些我自己并不了解的 x86 微体系结构。CPU vs IO bound 很可能是出现的问题之一:“CPU bound”和“I/O bound”这两个术语是什么意思?
正如在:https ://stackoverflow.com/a/12172046/895245 中提到的,这几乎不可避免地涉及阅读 Agner Fog 的文档,该文档似乎比英特尔自己发布的任何文档都要好。
然而,希望步骤 1 和 2 将作为至少试验功能性非性能方面的基础,并快速查看指令在做什么。
TODO:在此处生成此类优化的最小有趣示例。
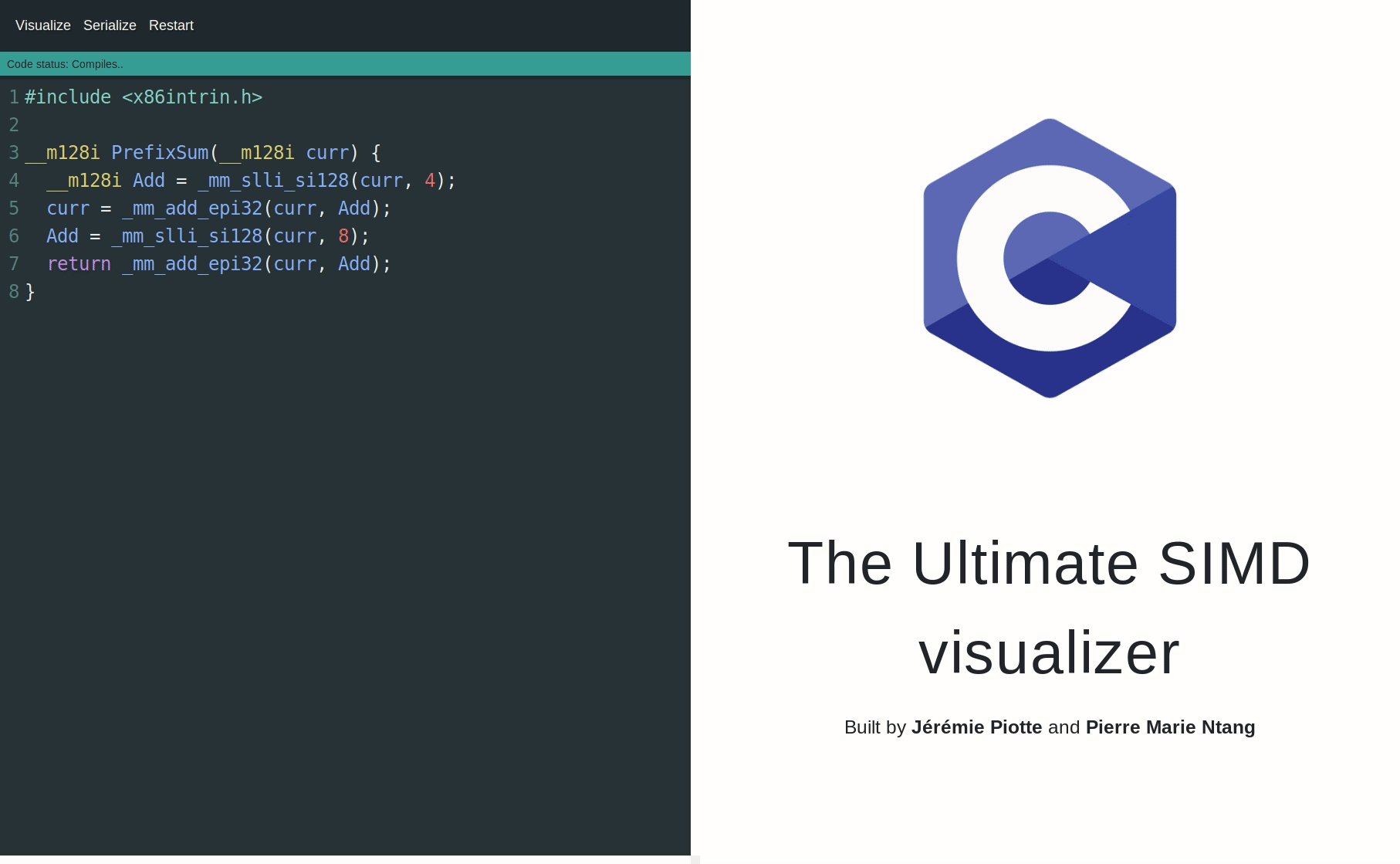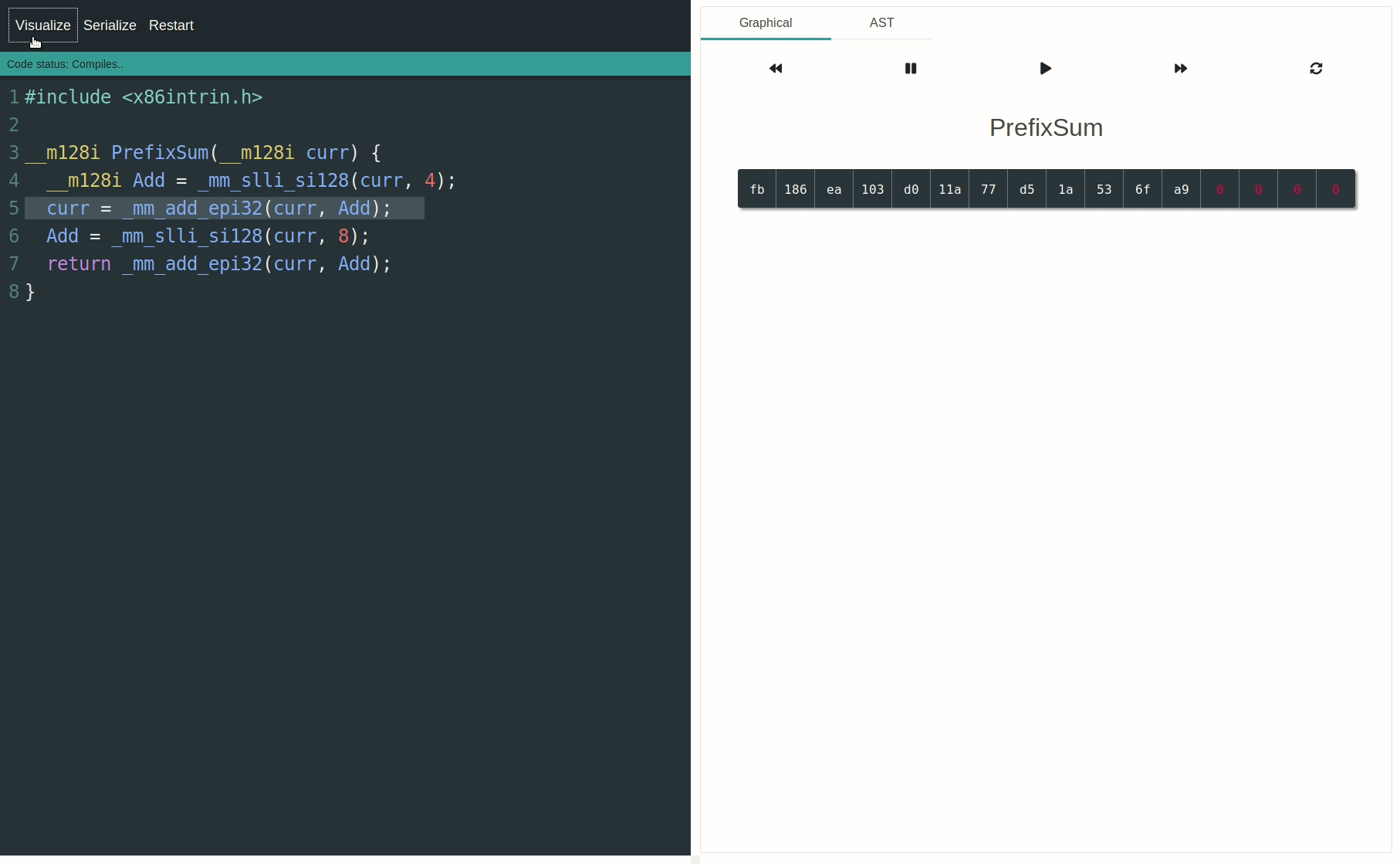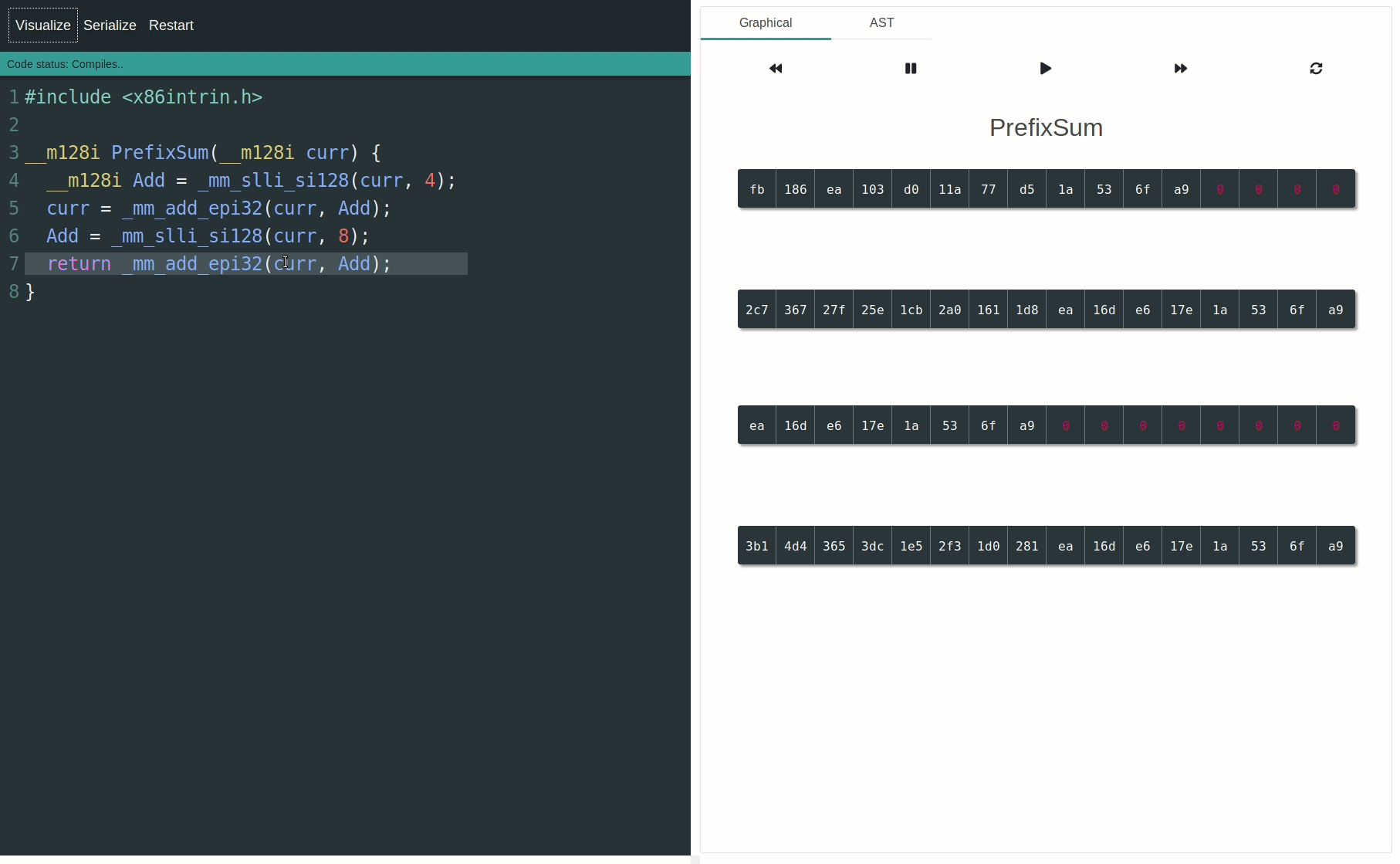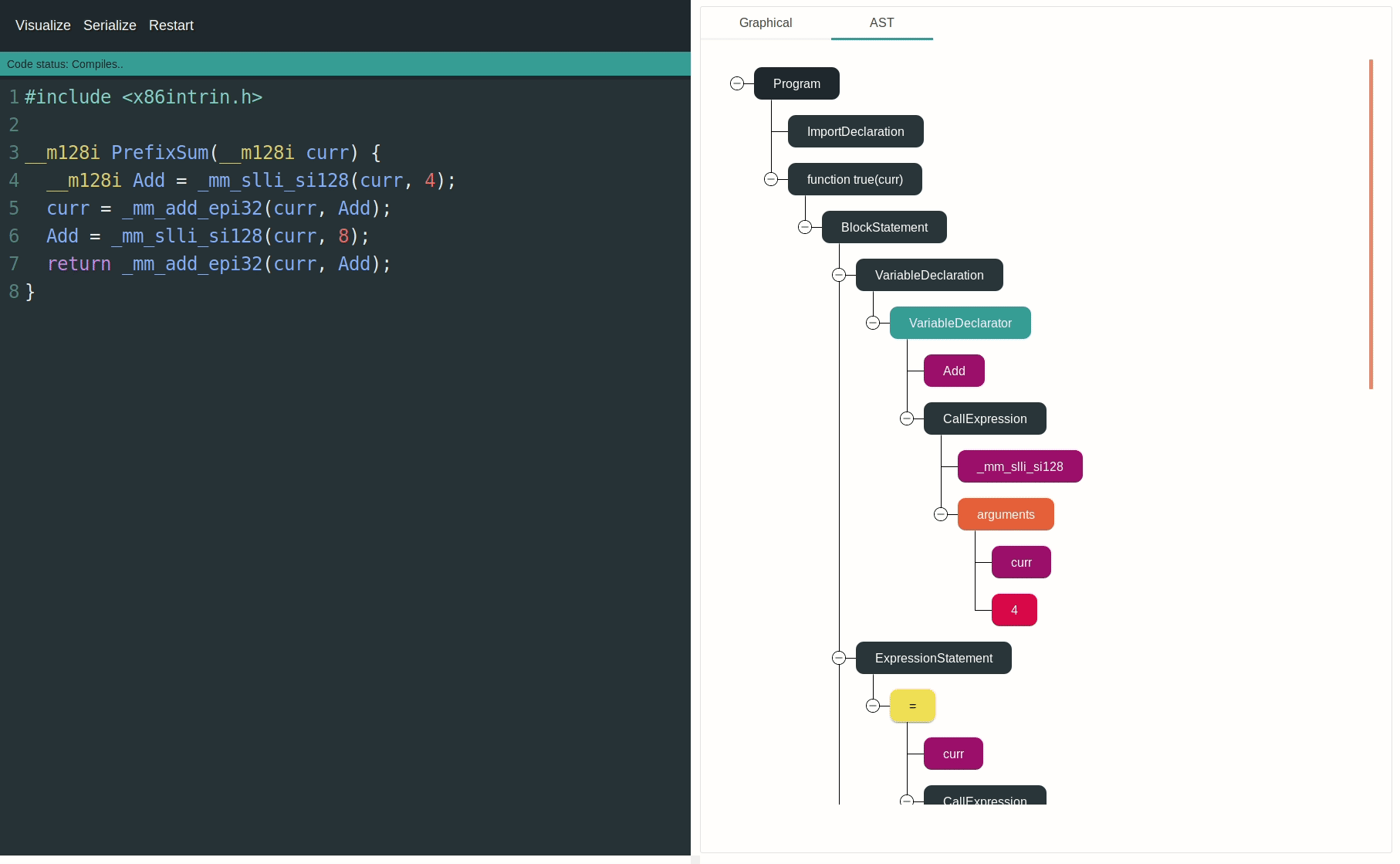
您可以使用SIMD-Visualiser以图形方式对操作进行可视化和动画处理。这将极大地帮助理解数据通道的处理方式