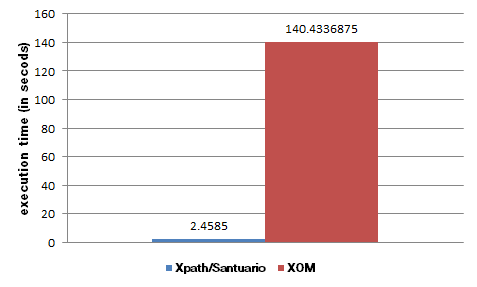
我有一个 1GB 大的 XML 文件。我正在使用 XOM 来避免 OutOfMemory 异常。
我需要规范化整个文档,但规范化需要很长时间,即使对于 1.5 MB 的文件也是如此。
这是我所做的:
我有这个示例 XML 文件,我通过复制 Item 节点来增加文档的大小。
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<Packet id="some" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Head>
<PacketId>a34567890</PacketId>
<PacketHeadItem1>12345</PacketHeadItem1>
<PacketHeadItem2>1</PacketHeadItem2>
<PacketHeadItem3>18</PacketHeadItem3>
<PacketHeadItem4/>
<PacketHeadItem5>12082011111408</PacketHeadItem5>
<PacketHeadItem6>1</PacketHeadItem6>
</Head>
<List id="list">
<Item>
<Item1>item1</Item1>
<Item2>item2</Item2>
<Item3>item3</Item3>
<Item4>item4</Item4>
<Item5>item5</Item5>
<Item6>item6</Item6>
<Item7>item7</Item7>
</Item>
</List>
</Packet>
我用于规范化的代码如下:
private static void canonXOM() throws Exception {
String file = "D:\\PACKET.xml";
FileInputStream xmlFile = new FileInputStream(file);
Builder builder = new Builder(false);
Document doc = builder.build(xmlFile);
FileOutputStream fos = new FileOutputStream("D:\\canon.xml");
Canonicalizer outputter = new Canonicalizer(fos);
System.out.println("Query");
Nodes nodes = doc.getRootElement().query("./descendant-or-self::node()|./@*");
System.out.println("Canon");
outputter.write(nodes);
fos.close();
}
尽管此代码适用于小文件,但在我的开发环境(4gb ram,64bit,eclipse,windows)上,1.5mb 文件的规范化部分需要大约 7 分钟
任何指向此延迟原因的指针都非常感谢。
PS。我需要对整个 XML 文档以及整个文档本身的段进行规范化。因此,使用文档本身作为论据对我不起作用。
最好的