几年前,我构建了一个探查器,并在 SO 上对其进行了描述,以回答我现在无法找到的其他一些问题,即如何构建探查器。
它基于至少部分自动化我使用了几十年的技术,这里给出了一个例子。它基于堆栈采样,关键在于如何呈现信息,以及用户经历的思考过程。
关于性能调整的一般信念,在学校教授(由几乎没有接触过实际软件的教授)并通过 50,000 名程序员不会出错的现象继续存在,我建议需要质疑并坚持更稳固的立足点。我远不是一个人有这种感觉,因为你可能会在 SO 周围巡游时收集到。
我认为分析器技术正在逐渐向堆栈采样和探索结果的方式发展(在我看来是更好的)。以下是我所依赖的见解(您可能会觉得有些不和谐):
发现性能问题以便修复它们和衡量性能是两个完全不同的任务。它们是手段和目的,不应混淆。
要发现性能问题,需要找出哪些活动占用了大量的挂钟时间,并且可以用更快的东西代替。
此类活动的好处在于,它们需要时间这一事实使它们暴露于程序状态的随机时间样本。
如果在您关心的时间间隔内采集样本,则不需要太多样本。即在等待用户输入的同时进行采样是没有意义的。为此,在我的分析器中,我让用户使用按键触发样本。
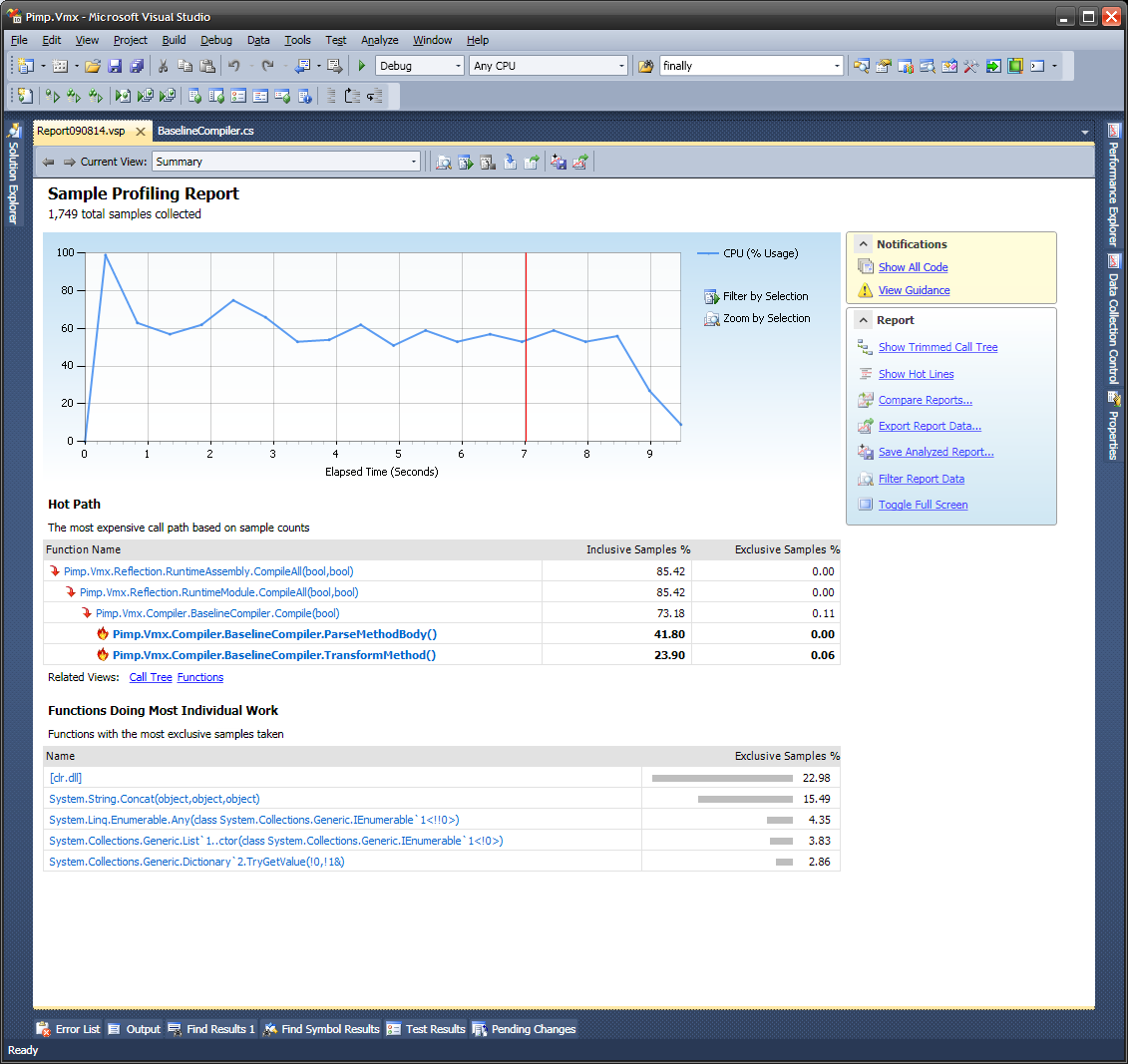
你不需要很多样本的原因是这个。任何给定的性能问题都会在感兴趣的时间间隔内花费一部分挂钟时间。该区间内的随机样本有 X 概率“在行为中捕获它”,因此如果抽取 N 个样本,则在行为中捕获它的预期样本数为 NX。该样本数的标准偏差为 sqrt(NX(1-X))。例如,如果 N = 20,X = 20%,您可以预期大约 2 到 6 个样本来显示问题。这为您提供了对问题的不精确测量,但它确实告诉您它值得修复,并且它为您提供了一个非常精确的位置,无需任何进一步的侦探工作。
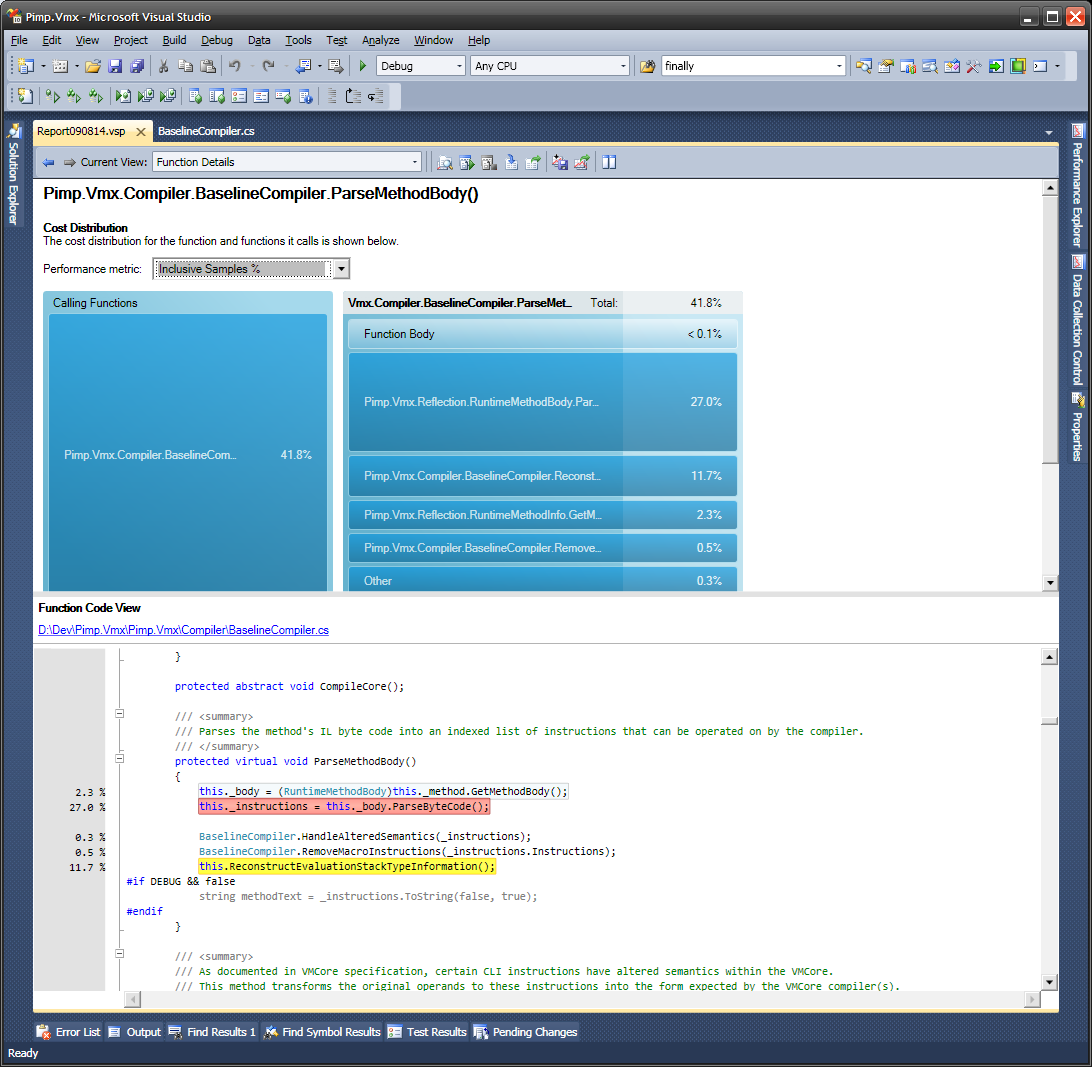
问题通常表现为比必要更多的函数、过程或方法调用,尤其是当软件变大、抽象层越多、堆栈层越多时。我首先寻找的是出现在多个堆栈样本上的调用站点(不是函数,而是调用语句或指令)。它们出现的堆栈样本越多,它们的成本就越高。我寻找的第二件事是“它们可以被替换吗?” 如果它们绝对不能用更快的东西代替,那么它们就是必要的,我需要寻找其他地方。但通常它们可以被替换,我得到了很好的加速。因此,我正在仔细查看特定的堆栈样本,而不是将它们汇总为测量值。
递归不是问题,因为一条指令的成本是它在堆栈上的时间百分比的原则是相同的,即使它调用自己也是如此。
这不是我一次做的事情,而是连续通过。我解决的每个问题都会使程序花费更少的时间。这意味着其他问题在时间上所占的比例更大,使它们更容易被发现。这种效应复合,因此通常可以实现显着的累积性能改进。
我可以继续,但我祝你好运,因为我认为需要更好的分析工具,你有一个很好的机会。
{kind=link}
{kind=link}