我开始深入研究图形数据库,但我不知道这些图形是如何在内部存储的。假设我有这张图(取自维基百科):
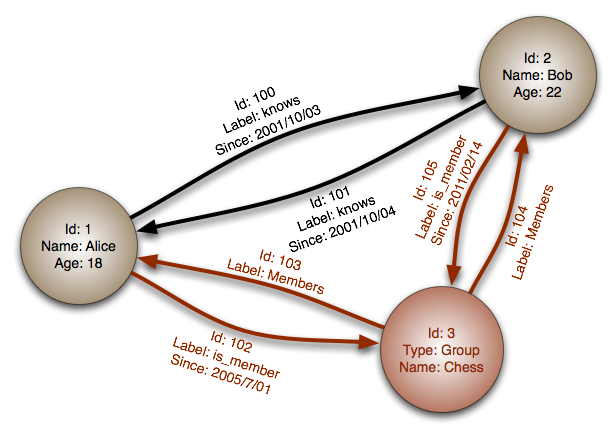
如何将此图序列化为键值对象?(例如 Python 字典)
我想象两个字典,一个用于顶点,一个用于边缘:
{'vertices':
{'1': {'Name': 'Alice', 'Age': 18},
'2': {'Name': 'Bob', 'Age': 22},
'3': {'Type': 'Group', 'Name': 'Chess'}},
'edges':
{'100': {'Label': 'knows', 'Since': '2001/10/03'},
'101': {'Label': 'knows', 'Since': '2001/10/04'},
'102': {'Label': 'is_member', 'Since': '2005/7/01'},
'103': {'Label': 'Members'},
'104': {'Label': 'Members'},
'105': {'Label': 'is_member', 'Since': '2011/02/14'}},
'connections': [['1', '2', '100'], ['2', '1', '101'],
['1', '3', '102'], ['3', '1', '103'],
['3', '2', '104'], ['2', '3', '105']]}
但我不确定,这是否是最实际的实现。也许“连接”应该在“顶点”字典中。那么,使用键值对象实现图形数据存储的最佳方式是什么?我可以在哪里阅读更多关于它的信息?
可能相关,但不重复:如何在某些数据结构中表示一个奇怪的图