堆栈在微处理器中的作用是什么?
42012 次
10 回答
4
在最低级别,堆栈是某些指令存储或检索数据的地方,以及在发生中断时存储数据的地方。微处理器各不相同,但有 5 种一般类型的堆栈特定指令:
- PUSH - 将数据放入堆栈
- POP(或 PULL)——从堆栈中“移除”数据
- CALL - 跳转到子程序并将返回地址放入堆栈
- RETURN - 通过使用堆栈顶部加载程序计数器从子程序返回
- INT(或 SWI)——软件中断;专门的 CALL
当发生处理器中断时(由于外部设备),CPU 会将当前程序计数器和(通常)标志寄存器保存在堆栈上并跳转到处理子程序。这允许处理子例程处理中断并返回到 CPU 正在执行的任何操作,并保留其当前状态。
虽然微处理器一次只有一个堆栈处于活动状态,但操作系统可以使它看起来好像有多个堆栈。至少一个用于操作系统,一个用于每个进程,一个用于每个线程。事实上,线程本身可能实现多个堆栈。
在更高的层次上,任何用于实现线程的语言通常都会将堆栈用于其自身目的来存储函数调用参数、局部变量和函数调用返回值(在这里粗略地说——请参阅您的语言的低级具体细节的文档)。
这样就结束了我对堆栈的自下而上的解释。
于 2009-07-11T18:14:14.050 回答
2
在计算的早期,子程序调用是通过在每个子程序中都有一个内存 RAM 字来处理的,以指示它是从哪里调用的。要调用子例程,可以执行以下操作:
使用 #LABEL_123 加载 foo_return 去富 #LABEL_123: ...从 foo 返回后执行的代码 富: ... 做东西 转到 foo_return
这种模式可以通过让调用者将返回地址放入寄存器并让例程将其存储到入口处的“返回”点来优化。这种模式有效,但也存在一些问题。它不仅通常会浪费内存——它也无法处理递归或重入代码。添加堆栈可以通过让调用者简单地说“将返回地址存储在合适的地方”来简化代码,而不会干扰任何先前的调用,并且被调用函数只需说“返回到最近的调用者没有还没有回来”。这允许开发可重入代码,并且意味着只需要存储足够的返回地址来处理实际发生的最深嵌套的函数调用链。
于 2012-02-08T16:57:10.350 回答
1
堆栈用于在函数调用期间存储和检索返回地址。它在嵌套函数调用或递归函数调用期间得到了很好的使用。它还用于将参数传递给函数。
在微处理器上,它还用于在上下文切换之前存储状态寄存器内容。
干杯
于 2009-07-11T16:50:27.370 回答
1
这取决于微处理器。通常它的作用是保持局部变量和函数的参数。
实际上它不在微处理器中,而是在中央存储器中。
于 2009-07-11T16:25:23.460 回答
0
http://www.hobbyprojects.com/microprocessor_systems/images/stack.gif
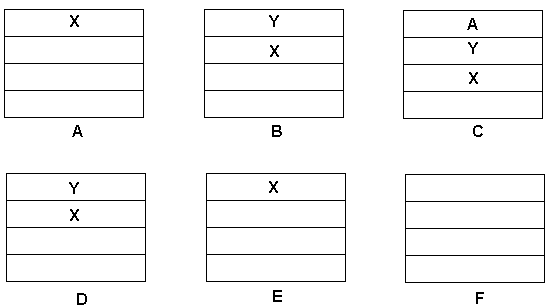{kind=link}
堆栈是数据的临时存储。
CPU 可能会在处理其他数据时将重要数据推入堆栈。
当它完成该任务时,它将保存的数据从堆栈中拉出。
它就像一堆盘子。底板是被压入堆栈的第一位数据。顶板是最后要推送的数据。顶板先拉,底板是最后拉的数据。它是一个后进先出的堆栈。
在图中,X 是第一个被推送的,然后是 Y,最后是 A。CPU 去处理其他数据。完成该任务后,它会返回以提取保存的数据。首先拉A,然后拉Y,最后拉X。
推送数据的指令是PHA。只有累加器中的数据才能被压入堆栈。如果其他数据先传输到累加器,则可以推送其他数据。
从栈中取出数据的指令是PLA。堆栈上的数据被传输到累加器。
6502 堆栈由 256 个字节组成,占用第 1 页,地址为 256 到 511。
于 2009-07-14T20:34:25.097 回答
0
只是为了增加这些答案中的一些,一些低端的微处理器,如 PIC 线有一个硬件调用堆栈,这意味着它不能像在硬件中那样动态分配。
这样做的含义是,在堆栈用完之前,您只能进行这么多的函数调用;当然,软件也是如此,但通常基于硬件的堆栈可能非常有限,并且可能需要您重新考虑您的程序以“扁平化”您的函数调用。
于 2009-07-14T20:42:54.707 回答
0
一些微处理器有堆栈寄存器来提高效率,看看维基百科中的SPARC 文章;其他人有一个微程序的微堆栈......事实上,这是一个非常广泛的术语。
于 2009-07-11T16:39:33.493 回答
0
堆栈是 LIFO(后进先出)缓冲区的实现。FIFO(先进先出)也称为队列。但回到后进先出。
x86 架构中的堆栈允许软件设计人员省去 RISC 处理器中的返回地址寄存器和中断返回地址寄存器等奇怪的东西。一切都可以驻留在堆栈上,这意味着有一个标准化和统一的方法来处理调用/返回、参数/局部变量和中断/中断返回。在单独的堆栈上使用该方法简化了多线程的实现。
相比之下,RISC 使用类似堆栈的缓冲区,尽管它们将相关信息的重要部分保留在其他地方。RISC“堆栈”可能更快(不确定),但它们肯定比 x86 更难理解。
于 2011-02-19T21:54:35.163 回答
-5
实际上堆栈不是处理器的术语,它用于语言的例程调用。例程可以使用堆栈获取参数和保存局部变量,也可以调用其他例程。
于 2009-07-11T16:28:48.023 回答