这是Gilbert 和 Lynch对分区容差的定义
当网络被分区时,从分区的一个组件中的节点发送到另一个组件中的节点的所有消息都将丢失。
让我们将集群分成两个分区:第一个仅包含协调器,第二个包含所有其他节点。这样协调器将无法联系任何副本,并会以错误响应。是否允许分区容错系统?

这是Gilbert 和 Lynch对分区容差的定义
当网络被分区时,从分区的一个组件中的节点发送到另一个组件中的节点的所有消息都将丢失。
让我们将集群分成两个分区:第一个仅包含协调器,第二个包含所有其他节点。这样协调器将无法联系任何副本,并会以错误响应。是否允许分区容错系统?
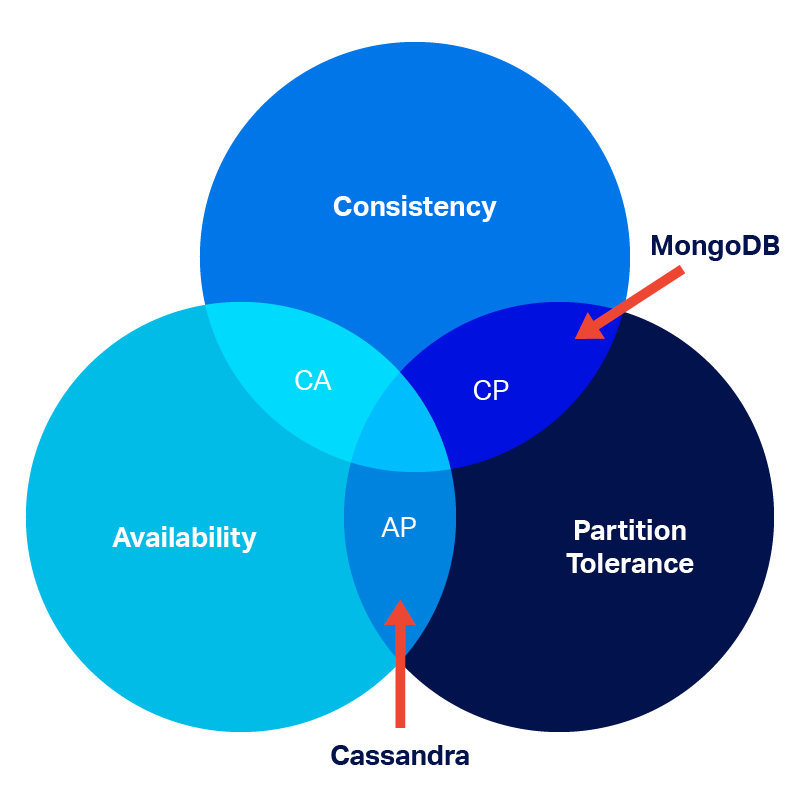
更具体地说,我认为问题是Cassandra 在面对这样的Partition时保留了其他两个CAP属性中的哪一个。
答案取决于配置的一致性级别。对于写入,存在ANY一致性级别。在这个一致性级别,只要启用了提示切换,协调器就会记录写入并维护可用性。在分区解决之前,连接到其他协调器的客户端将无法看到更新的值,因此读取不会是Consistent。如果选择了更强的一致性级别,则客户端明确配置Consistency over Availability。
那么当读取协调器单独位于分区中时,Cassandra(鉴于它不一定将所有数据复制到所有节点)是否可以被视为AP ?如果它响应一个对我来说听起来像Consistency的错误,如果它响应一个空的结果集,因为数据不在它的分区中,那么那将是Availability。由于最弱的读取一致性级别是ONE- 需要至少一个副本来响应,因此 Cassandra 选择了前者:如果协调器本身不是拥有所请求数据的副本之一,那么读取将超时并且不可用。与写入一样,任何更强的读取一致性级别都会显式配置 Cassandra 以使其行为更加一致以可用性为代价。
所以“协调者”节点不是一个持久的或类似“领导者”的定义。它几乎随每个查询而变化。如果有一个非令牌感知操作需要一个协调器节点,并且该协调器突然与其余的协调器分开,则该查询将失败。
下一个查询(或重试)将选择一个新节点作为协调器。唯一的问题是,某些数据行会少一个副本(存储在分区节点上的数据)。但是,只要您正在查询ONE并且 RF >= 2,集群就会继续运行,就像什么都没发生一样。
所以“是的”,Cassandra 绝对是分区容忍的。
注意:这就是为什么使用令牌感知负载平衡策略很重要的原因。这样,驱动程序会选择包含所需数据的节点之一作为“协调器”。在一致性ONE时,操作在本地完成,并从等式中取出一个网络跳。
{kind=link}